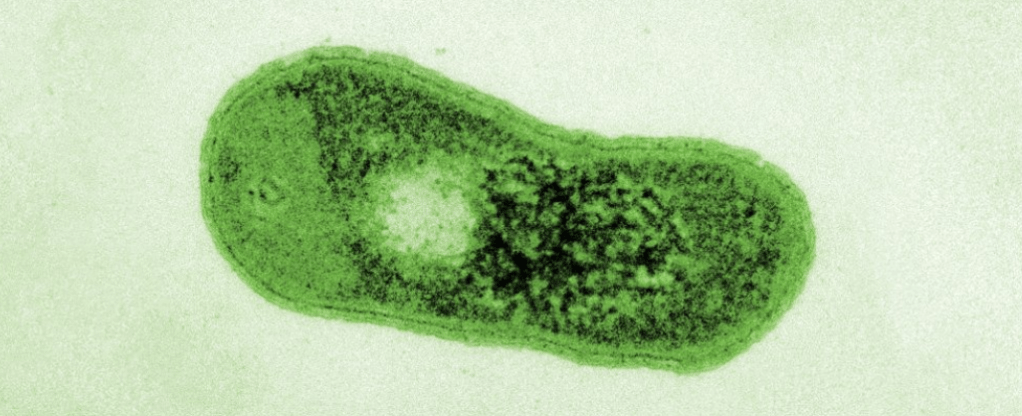
SEM en falso color de Gemmatimonas phototrophica. (Jason Dean/Czech Academy of Sciences)
El hallazgo más reciente de bacterias fototróficas, (Zehg et. al., 2014), corresponde a la especie Gram-negativa Gemmatimonas phototrophica, una inusual bacteria fotoheterótrofa facultativa incapaz de fijar carbono a partir de CO2, que crece igualmente bién en obscuridad, de manera que la fotofosforilación complementa la fosforilación oxidativa.
Perteneciente al phillum Gemmatimonodota, fué colectada por primera vez en un lago al occidente del desierto de Gobi, siendo el primer reporte del grupo con evidencia de fotosíntesis anoxigénica.
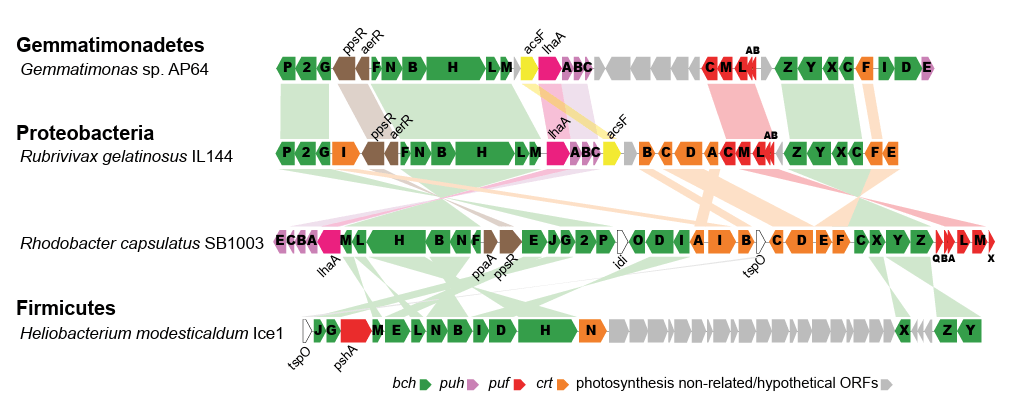
Tras realizar el estudio genómico correspondiente, Zehg et. al, op. cit, identificaron un Cluster fotosintético completo (PGC) cuyo análisis comparativo con otras especies microbianas sugirió una adquisición temprana via transferencia horizontal desde una bacteria púrpura fotosintética, ver fig 1.
Éste hallazgo es la primera evidencia de transferencia horizontal fototrófica entre phyla bacterial distante, lo que proporciona nuevos y valiosos elementos a tener en cuenta en la evolución de la fotosintesis microbiana.
Figura 1. Referenciación genética del PGC de AP64 comparado con Proteobacterias (Rubrivivax gelatinosus y Rhodobacter capsulatus), y Firmicutes (H. modesticalum). Nótese la coincidencia particularmente con R. gelatinosus. Fuente: Zeng et.al. 2014: http://www.pnas.org/cgi/doi/10.1073/pnas.1400295111
Con éste nuevo encuentro ya son siete los grupos bacterianos fotosintetizadores descritos a la fecha: Cyanobacterias, Proteobacterias alfa y gamma (purpura no sulfurosa y sulfurosa respectivamente), Chlorobi (GSB) , Chloroflexi (FAP) , Firmicutes (Heliobacterias) , Acidobacteria y finalmente Gemmatimonadetes (Gemmatimonas).
El complejo LHC/RC, denominado en este grupo RC-dLH precenta una pseudosimetría C8, con el complejo antena (LHC) de anillo doble rodeando el centro de reacción (RC).
COMPLEJO ANTENA LHC
LHC está constituido por dos anillos concéntricos de corte ligéramente elipsoidal. El anillo interno, LH1, similar al complejo LHI de bacterias púrpura, recibe energía lumínica del anillo externo y la transmite al centro de reacción. El anillo externo, LHh, responsable de capturar la energía solar y transmitirla a los pigmentos de anillo interno, es un nuevo diseño de complejo antena solo presente en este grupo bacteriano, ver Fig.1.
Figura 1. Estructura general del complejo RC-dLH. Se excluyen en la figura los pigmentos responsables de la cadena de transporte de electrones en el centro de reacción.
ANILLO INTERNO
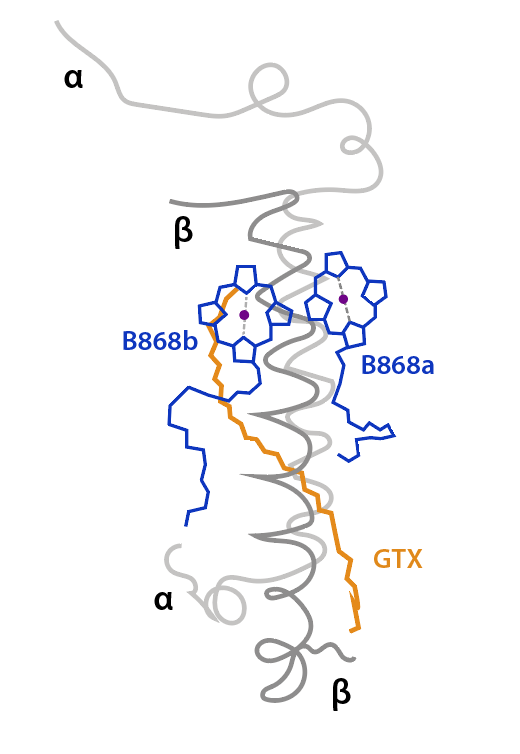
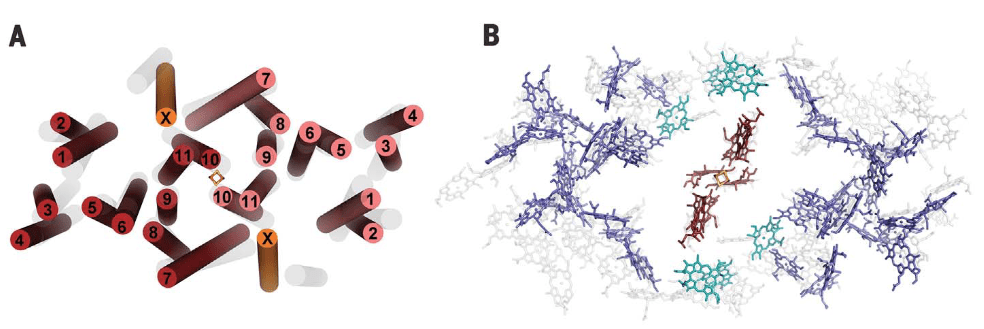
El anillo interno, de estructura cilíndrica,está conformado por 16 unidades heterodiméricas de polipéptidos transmembrana α/β , α internas, β externas al anillo. Entre las subunidades α y β de cada heterodímero se ligan no covalentemente un par de pigmentos BChl a y un all-Trans carotenoide, Gemmatoxanthina, con bandas de absorción entre 400 y 600 nm, picos a 478, 507 y 542 nm. (Zehg et. al., 2014).
El par Bchl, B868a/B868b, absorbe energía a 868 nm, sus planos tetrapirrólicos son perpendiculares a la superficie citoplasmática, plano XZ, ver fig.2, y su posición es distal respecto al centro RC. El caroteno, con orientación radial al complejo, atravieza el complejo desde extremo distal a proximal, tiene función fotoprotectora y de captura y transmisión de energía a las Bchl, ver Fig.2.
Figura 2. Unidad heterodimérica y pigmentos asociados al anillo LH1. Simplificado de Quian et.al., 2022.
ANILLO EXTERNO
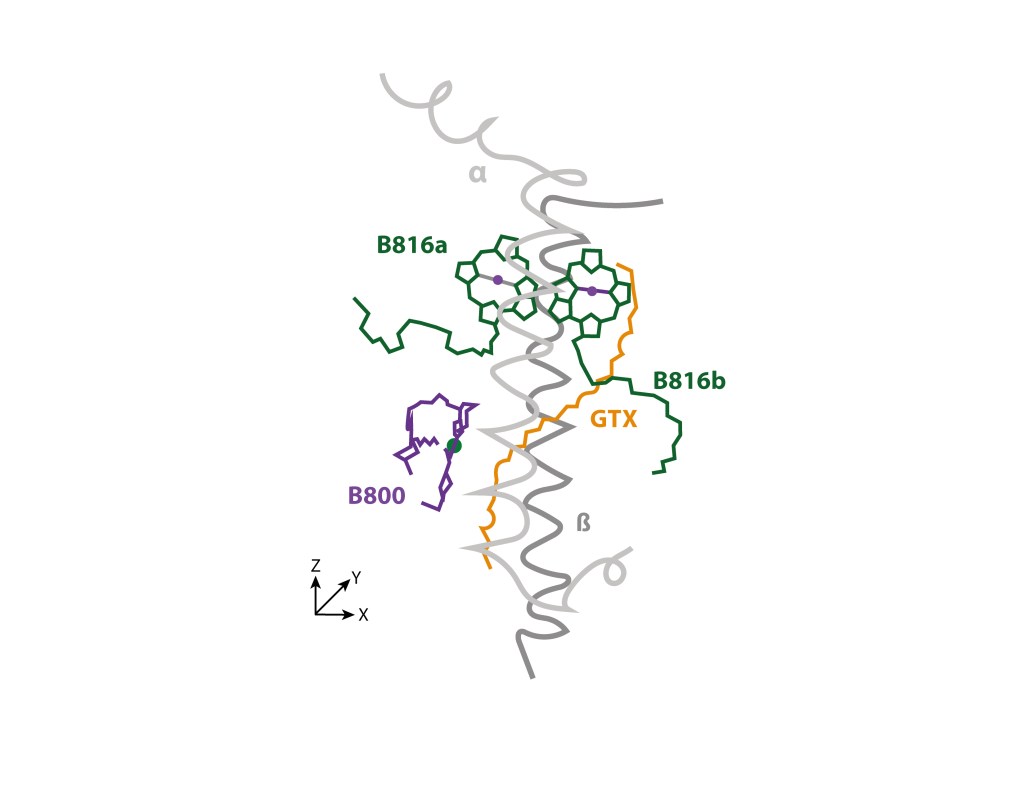
El anillo externo, de estructura ligeramente cónica, denominado LHh, está conformado por 24 heterodímeros polipeptídicos α/β, cada uno con un par de clorofilas BChl B816 en posición distal, alineadas en el plano XZ, una clorofila BChl B800 proximal alineada en el plano YZ, y un caroteno GTX radial atravezando el complejo, de manera similar a su posición en LH1, quedando en consecuencia los tres BChl con sus planos tetrapirrólicos perpendiculares al plano XY de la superficie citoplasmática. ver Fig.3.
Figura 3. Unidad heterodimérica y pigmentos asociados al anillo LHh. Simplificado de Quian et.al., 2022.
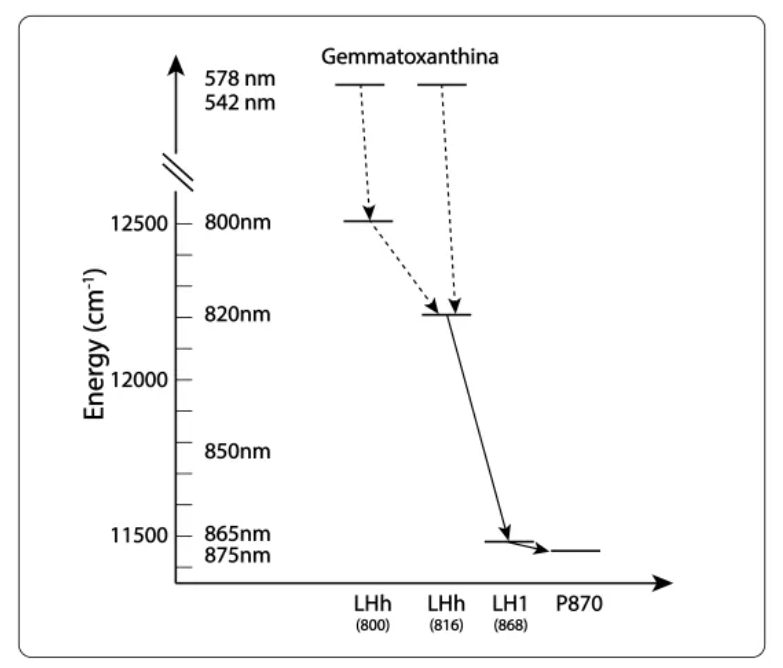
La Fig 4 representa la transferencia de energía entre y dentro de los dos anillos LH1 y LHh. Aunque no está referenciado en la literatura, las transferencias electrónicas deben obedecer a resonancia no radiativa de Förster.
Fig 4. Cinética de transferencia de energía en el complejo RC-dLH1.
CENTRO DE REACCIÓN RC
La arquitectura general del centro de reacción del grupo es similar al presente en proteobacterias fototróficas, ver lectura de bacterias púrpura, con un heterodímero polipeptídico principal conformado por las subunidades L y M y un citocromo c soluble periplasmático responsable del transporte cíclico de electrones desde el citocromo BC1 hasta RC.
En cuanto a los pigmentos involucrados en RC, equivalentes a los presentes en bacterias púrpura, ver lectura correspondiente, comprenden un par especial Bchla 870 receptor primario de la energía lumínica proveniente de LH1, un par ACC accesorio, ver Fig 1., dos moléculas de bacteriopheophytin a (BPhe a), un carotenoide del tipo spirilloxanthina, tres menaquinona-8 (MQ8), una en posición QA, una en posición QP y una tercera nueva adyacente a la cara interna del anillo LH1, cerca al sitio QB, designada QF.
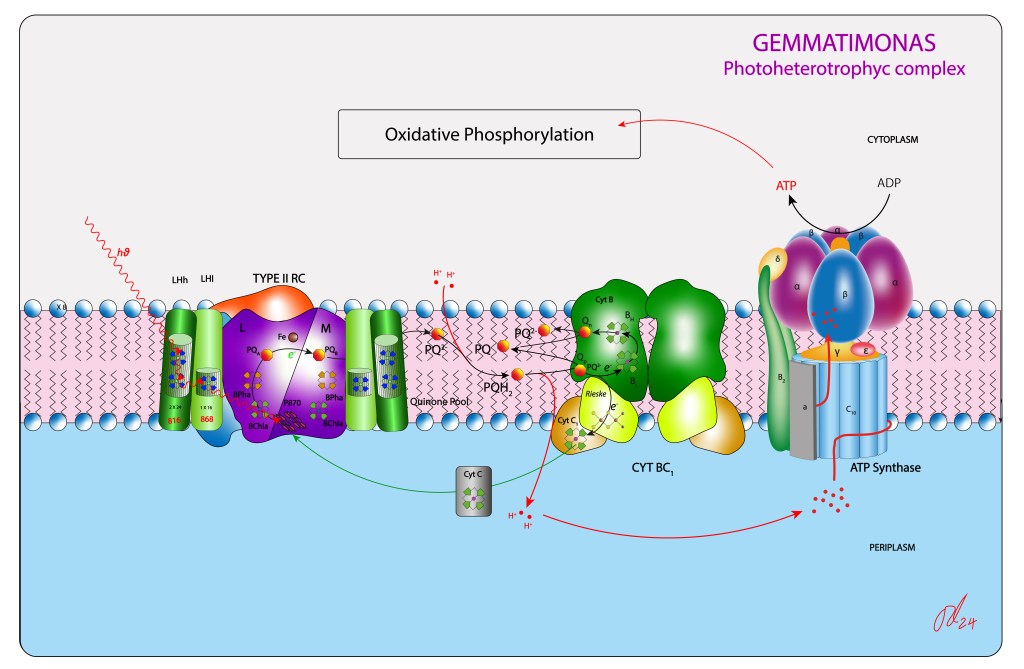
La Figura 5 resume el complejo fototrófico de este nuevo grupo.
Figura 5. Aparato fototrófico en Gemmatimonas
METABOLISMO
La transferencia horizontal de un plásmido proveniente de bacterias púrpura fotosintéticas fué seguramente el elemento responsable de la adquisición de la maquinaria fototrófica en la especie en estudio.
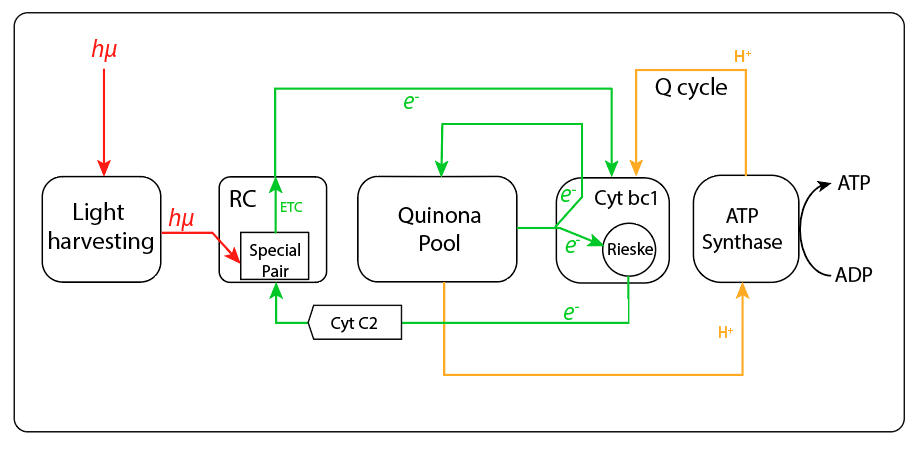
Sin embargo, la transferencia no involucró el genoma responsable de otras piezas requeridas para una función fototrófica completa. Así, en la especie no se ha evidenciado presencia de sistemas de captura de electrones desde moléculas donoras, orgánicas o inorgánicas, de manera que la función fototrófica depende exclusivamente de la retroalimentación cíclica de electrones desde el citocromo bc1 hacia el centro de reacción mediado por un cyt c como transportador cíclico de electrones. Adicionalmente, no se han evidenciado tampoco rutas reductoras asociadas a la cadena fototrófica, tipo ciclo reverso TCA, ruta reductora de las pentosas, ciclo del hidroxypropianato, etc, vías metabólicas características de los demás grupos bacterianos fototróficos, de manera que el ATP, producto final del complejo adquirido, alimenta directamente el complejo responsable de la fosforilación oxidativa, ver Fig.5. Esta nueva ruta alterna de síntesis de ATP le permite a la especie ahorrar moléculas orgánicas donoras de carbono en presencia de luz.
Figura 5. Cibernética de captura de eneregía en Gemmatimonas.
En cuanto al aporte del complejo LHC/RC a la función respiratoria, Koblízek et.al, 2020 resaltan varios puntos:
Exposición de irradiancia lumínica de 100 μmol de fotones m-2 S-1 incrementó el crecimiento de las colonias bacterianas en aproximadamente un 30% , lo que sugiere que el complejo bioquímico adquirido optimiza la captura de energía durante exposición directa a la radiación solar.
La exposición a radiación solar mejoró igualmente la asimilación de compuestos orgánicos. Así, a intensidades por encima de 400 μmol de fotones m-2 S-1 , la asimilación de glucosa fué 2.77 veces mayor que la la obtenida en obscuridad.
No se evidencian mecanismos adaptativos a la luz, de modo que se produce la misma cantidad de complejos PS tanto en luz como en obscuridad.
En contraste con otras bacterias anoxigénicas fototróficas que crecen aeróbicamente y sintetizan BChl a solo en obscuridad, la especie en estudio no crece bajo condiciones totalmente aeróbicas y produce BChl a incluso bajo luz contínua.
En conclusión, G. phototrophica es un fotoheterótrofo típico facultativo, utiliza carbono orgánico para su biomasa y metabolismo, pero la luz mejora significativamente su crecimiento.
Finalmente, el hallazgo de la especie demuestra la capacidad bacteriana de importación via transferencia horizontal de genomas de función completa, lo que abre nuevas posibilidades para entender la evolución bacteriana. Para ilustrar el alcance del hallazgo, la presencia de dos complejos fotosintéticos PSI y PSII complementarios en cyanobacterias se ha explicad bajo la teoría de duplicación, evolución y diferenciación interna de los dos complejos fotosintéticos en una especie bacteriana para una posterior combinación evolutiva de los dos complejos en una sola maquinaria altamente eficiente.
El hallazgo abre otras posibilidades, con evolución a partir de transferencias horizontales interespecíficas, eventualmente interphila, entre donor PSII (o PSI) a aceptor con la contraparte complementaria.
BIBLIOGRAFÍA CITADA Y SUGERIDA
[1] P. Qian et al., 2.4-Å structure of the double-ring Gemmatimonas phototrophica photosystem. Sci. Adv. 8, eabk3139 (2022)
[2] R. E. Blankenship, Molecular Mechanisms of Photosynthesis (John Wiley & Sons, ed. 2, 2014), pp. 312.
[3] P. Qian, C. A. Siebert, P. Y. Wang, D. P. Canniffe, C. N. Hunter, Cryo-EM structure of the Blastochloris viridis LH1–RC complex at 2.9 Å. Nature 556, 203–208 (2018)
[4] Y. Zeng, F. Y. Feng, H. Medová, J. Dean, M. Koblížek, Functional type 2 photosynthetic reaction centers found in the rare bacterial phylum Gemmatimonadetes. Proc. Natl. Acad. Sci. U.S.A. 111, 7795–7800 (2014).
[6] M. Koblízek, M. Dachev, D. Bína, Nupur, K. Piwosz, D. Kaftan, Utilization of light energy in phototrophic Gemmatimonadetes. Journal of Photochemistry & Photobiology, B: Biology 213 (2020) 112085
[7] M. Dachev, D. BõÂna, R. Sobotka1, L. MoravcovaÂ, Z. Gardian, D. Kaftan, V. louf, M. Fuciman, T. PolõÂvka, Mi KoblõÂzÏek, Unique double concentric ring organization of light harvesting complexes in Gemmatimonas phototrophica. journal.pbio. (2017) 2003943
La clase Heliobacterias (Orden Heliobacteriales, Phyllum Firmicutes), corresponde a un grupo muy especializado de bacterias fotoheterótrofas Gram+.
Descrito por primera vez en 1983 por Ghest y colabordores [3], a la fecha tiene definidos dos clados, cuatro géneros (Heliobacterium, Heliobacillus, Heliophilum y Heliorestis) y diez especies.
Las especies son mayormente terrestres, raramente acuáticas, anaerobias estrictas, prosperando en suelos anóxicos, muchas veces asociadas en relaciones mutualistas con cultivos de arroz, y al igual que las especies heterótrofas del grupo, presentan endosporulación. Algunas especies (Heliobacillus movilis, Heliobacterium modesticalium) han sido reportadas en suelos proximos a fuentes termales. H. modesticalium, hallada Islandia, ha sido una de las especies mejor estudiadas.
Considerado a nivel bioquímico un grupo minimalista, exhibe el aparato bioquímico de captura de energía mas simple dentro de todos los grupos bacterianos fototrófos y fotosintéticos reportados a la fecha. Su hallazgo ha aportando significativamente al entendimiento de la evolución de la fotosíntesis, se considera un grupo muy primitivo, con razgos bioquímicos ancestrales conservados.
Las Heliobacterias son incapaces de fijar carbono a partir de CO2, por lo que se considera un grupo bacteriano fotoheterótrofo, no fotosintético. Dependiendo de las condiciones ambientales, utilizan distintos compuestos como fuentes de electrones: H2S y compuestos orgánicos en suelos alcalinos, Fe2+, H2, succinatos y piruvatos en ambientes reductores y ácidos orgánicos en aguas termales.
CAPTURA DE ENERGÍA
A diferencia de los demás grupos bacterianos fotótrofos, las Heliobacterias no presentan complejos antena exclusivos a la función de captura de energía lumínica.
Su centro de reacción, HbRC, integra en un solo complejo las funciones de captura de energía y tránsito ETC, con dos dominios claramente diferenciables para cada una de las funciones: Dominio antena y dominio RC.
ESTRUCTURA PROTEÍNICA
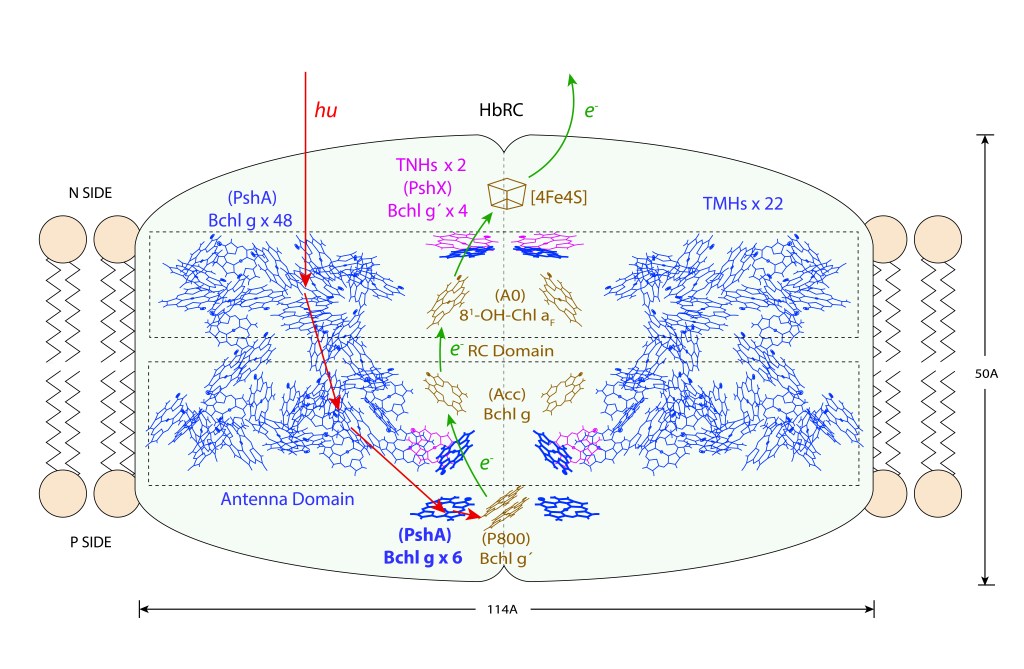
El complejo HbRC corresponde a un homodimero con simetría C2, 24 hélices transmembrana (TMHs) de las cuales 22 están asociadas al homodímero PshA y dos recientemente descritas a una nueva subunidad PshX, ver Fig.1 A. La distribución de pigmentos se describe en la Fig.1 B.
Figura 1. Arreglo de hélices Transmembrana (TMHs y pigmentos) en HbRC. Vista superior. Fuente: Gisriel et.al., 2017. En las imagenes, el autor superpone en gris las hélices (Fig A) y pigmentos (FigB) correspondientes a TMHs de PSI de plantas superiores.
DOMINIO ANTENA
El core del Dominio Antena corresponde a 54 bacterioclorofilas Bchl g (pigmentos de color azul) distribuidas en dos capas, ver Fig 2. De las 54 Bchl g, seis (azul intenso) son proximales al dominio RC, siendo probablemente las unidades responsables de la exitación del par especial de clorofilas.
Es importante resaltar que Gchl g , un isómero de Chl a, solo está presente en este grupo bacteriano.
En adición a las 54 Bchlg, cuatro Bchl g´ adicionales estan coordinadas por las subunidades Pshx (pigmentos magenta) igualmente proximales a RC. Bchl g´es un esteroisómero de Bchl g.
Figura 2. Heliobacterias: Estructura y dinámica general del complejo HbRC. Nota: La distribución y número de pigmentos en PshA es solo ilustrativo. para información mas rigurosa consultar Gisriel et.al., 2017.
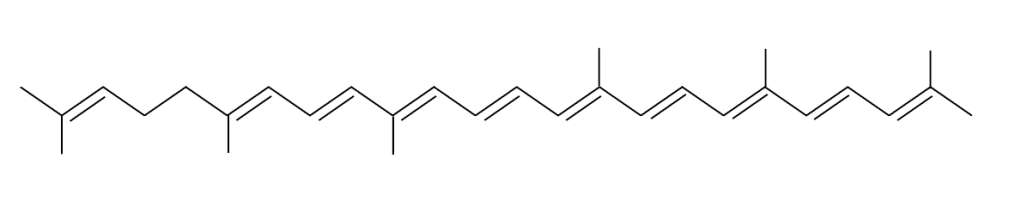
En adición a los pigmentos mencionados, dos moléculas de naturaleza lipídica y dos carotenos 4,4´ Diaponeurosporeno, uno por sumbunidad mioonodimérica, forman parte del Dominio Antena, ver Fig.3.
Figura 3. Estructura molecular C30 4,4´ diaponeurosporeno
DOMINIO RC
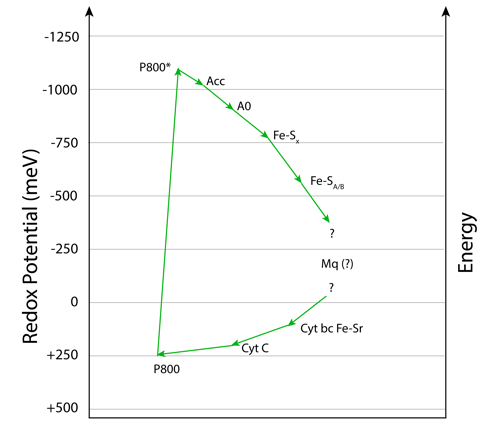
La ruta de transferencia electrónica (ETC) en Heliobacterias es similar a la de bacterias verdes del azufre, si bien la frecuencia de exitación es mucho más baja, ubicandose en el infrarojo cercano, alrededor de 798-800 nm. ver Fig.4.
En heliobacterias, P800 corresponde a Bchl g´, Acc a Bchl g y A0 a la clorofila 81-OH-Bchl aF.
La energía es finalmente entregada a una Fx del tipo [4Fe 4S] para luego reducir NAD+ a su forma NADH, mediante un intermediario FeS A/B.
Figura 4. Heliobacterias: Ruta de transferencia electrónica.
POOL DE QUINONAS
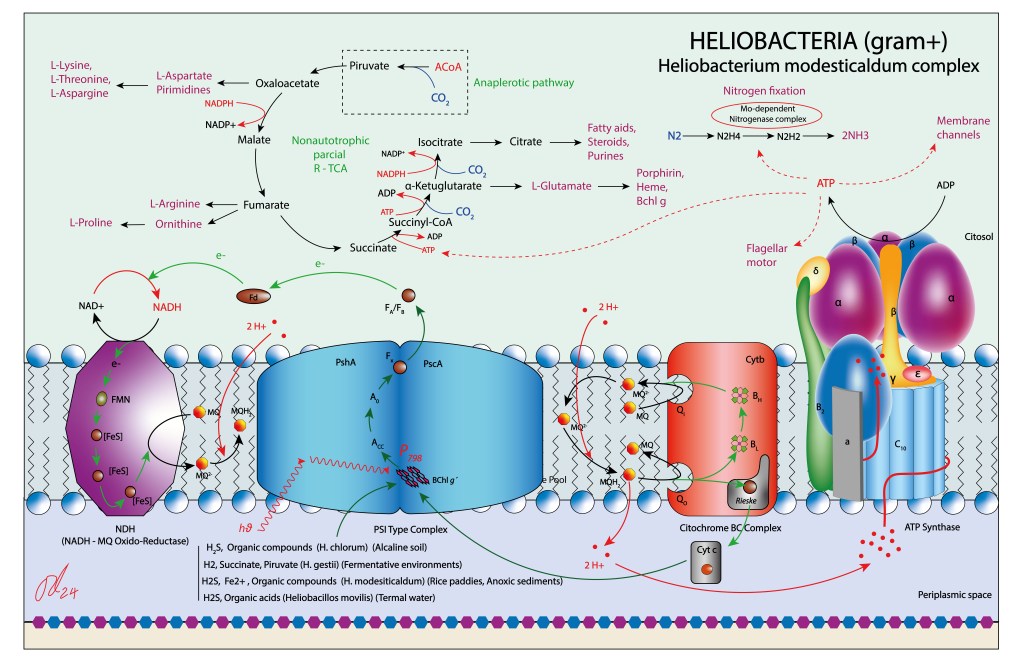
El pool de quinonas está representado por menaquinonas. En ausencia de un complejo II que pueda aportar directamente quinonas reducidas al pool, la enzina NDH puede estar soportando este rol, con NADH como fuente aportante de electrones.
CITOCROMO BC
Similar en función a los citocromos BC1 y B6f, realizan en este caso un flujo cíclico, con electrones transportados por un Cyt C soluble hacia el fotosistema, contribuyendo al aporte de electrones.
METABOLISMO REDUCTOR
Como ruta reductora, las Heliobacterias disponen de un ciclo parcial r-TCA . Dada la la ausencia de genes codificantes de ATP-Citrato Lyasa, el piruvato requerido por el ciclo debe ser obtenido por rutas anapleróticas, cedido por las plantas hospederas o a partir del sustrato.
Al igual que en GSB, los Ciclos CBB y Biciclo 3-HP están ausentes. En general las rutas bioquímicas del carbono aparecen muy simplificadas en Heliobacterias. En contraste, las rutas fijadoras de nitrógeno (Mo dependientes) son muy robustas. En este sentido podrían desempeñar en gramineas un soporte nitrificante similar al de Rhizobium, Bradyrhizobium y Sinorhizobium en leguminosas, si bién nunca conformando nódulos radiculares.
Puesto que son un grupo Gram+ carente de membrana interna, el espacio periplasmático desempeña la función del lúmen thylakoidal de cyanobacterias y del espacio intermembrana de bacterias púrpura, lo que les permite confinar el H+ requerido para la síntesis de ATP.
Como se mencionó anteriormente, la enzima transmembrana NDH (NADH-MQ Oxidoreductasa) forma parte de la bioquímica del complejo jugando un rol doble, transporte H+ hacia el espacio periplasmático y reducción de menaquinonas, lo que debe incrementar de manera significante la producción de ATP, ver Fig 5.
Figura 5 . Aparato fototrófico propio de Heliobacterias.
BIBLIOGRAFÍA RECOMENDADA
[1] Asao M, Madigan MT. Taxonomy, phylogeny, and ecology of the heliobacteria. Photosynth Res. 2010 Jun;104(2-3):103-11. doi: 10.1007/s11120-009-9516-1. Epub 2010 Jan 22. PMID: 20094790.
[2] Gisriel. C., Sarrou, I., Ferlez, B., Golbeck, J, J.H., Redding, K.E., and Fromme, R. (2017) Structure of a symmetric photosynthetic reaction center–photosystem. Science. 357:1021-1025
[3] Gest H. Discovery of the heliobacteria. Photosynth Res. 1994 Jul;41(1):17-21. doi: 10.1007/BF02184140. PMID: 24310008.
[4] Sattley WM, Blankenship RE. Insights into heliobacterial photosynthesis and physiology from the genome of Heliobacterium modesticaldum. Photosynth Res. 2010 Jun;104(2-3):113-22. doi: 10.1007/s11120-010-9529-9. Epub 2010 Feb 4. PMID: 20130998.
[5]Sattley WM, Madigan MT, Swingley WD, Cheung PC, Clocksin KM, Conrad AL Dejesa LC, Honchak BM, Jung DO, Karbach LE, Kurdoglu A, Lahiri S, Mastrian SD, Page LE, Taylor HL, Wang ZT, Raymond J, Chen M, Blankenship RE, Touchman JW 2008. The Genome of Heliobacterium modesticaldum, a Phototrophic Representative of the Firmicutes Containing the Simplest Photosynthetic Apparatus. J Bacteriol 190:. https://doi.org/10.1128/jb.00299-08
La convergencia evolutiva de los fotosistemas PSI y PSII ha sido sin lugar a dudas la innovación bioquimica de mayor impacto en la historia de vida en nuestro planeta.
Esta trascendental propuesta, desarrollada hace algo más de 2,500 millones de años por las cyanobacterias y luego transmitida por endosimbiosis seriada hacia algas y plantas superiores, permitió extraer del agua los electrones requeridos para mantener en funcionamiento la maquinaria fotosintética, llevandola a un nivel de eficiencia que terminó redireccionando el curso evolutivo de la vida.
El precio de dicha innovación fué muy alto.
El oxígeno liberado durante el proceso de oxidación del agua se convirtió en una amenaza para la vida, e incluso en una amenaza para la misma maquinaria que lo generó, lo que implicó involucrar una serie de rutas de protección de la maquinaria fotosintética, ver Fig 1.
Bajo condiciones ideales, y con un aparato fotosintético produciendo justo lo requerido, el oxígeno residual no es realmente una amenaza.
Pero variaciones en la disponibilidad de luz, cambios en PH, temperatura y humedad, restricciones en el acceso a CO2 , etc, implican cambios en los balances de las reacciones de oxidoreducción.
En estos casos, la oferta de electrones generados puede llegar a superar la capacidad de consumo por parte de la misma, lo que resulta en una cadena de trasporte de electrones ETC altamente reductora.
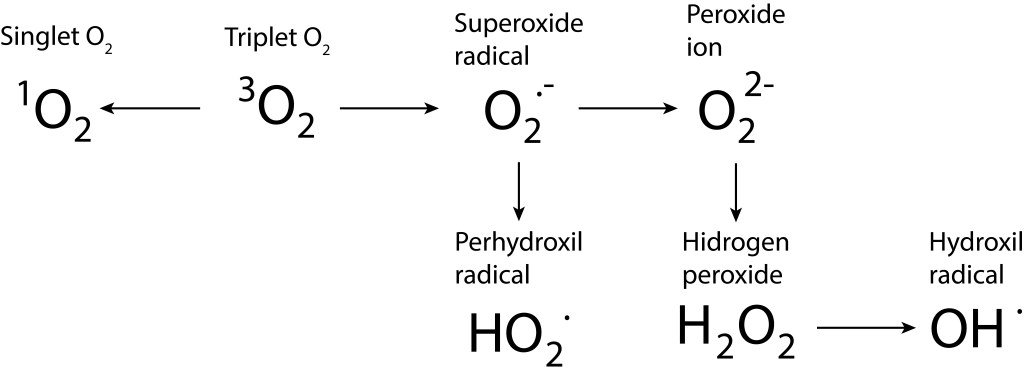
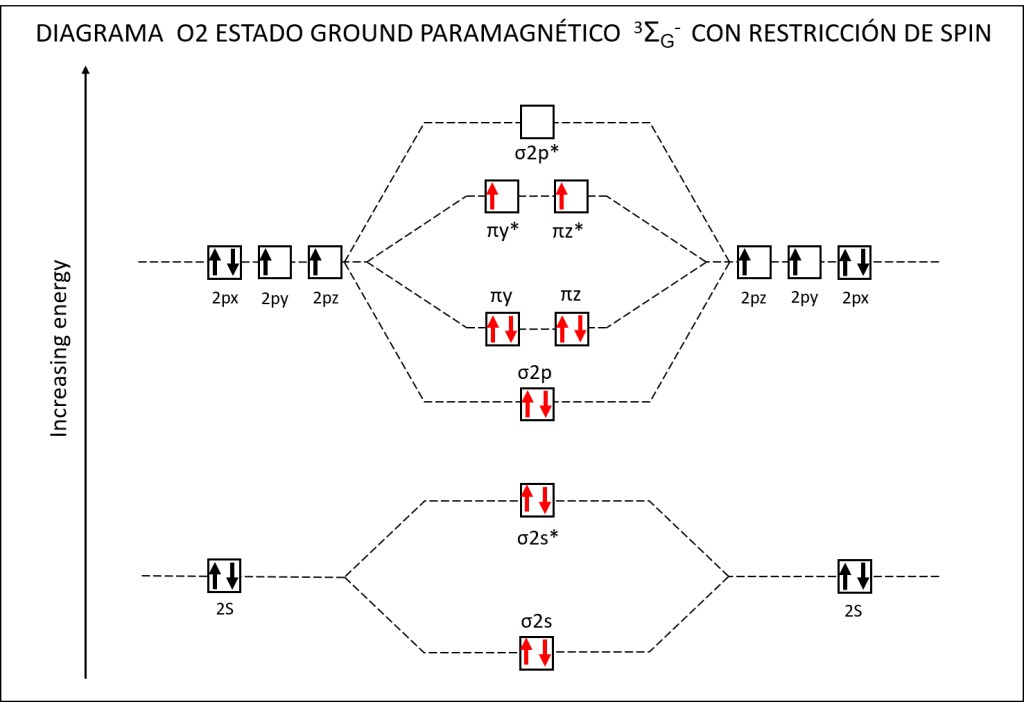
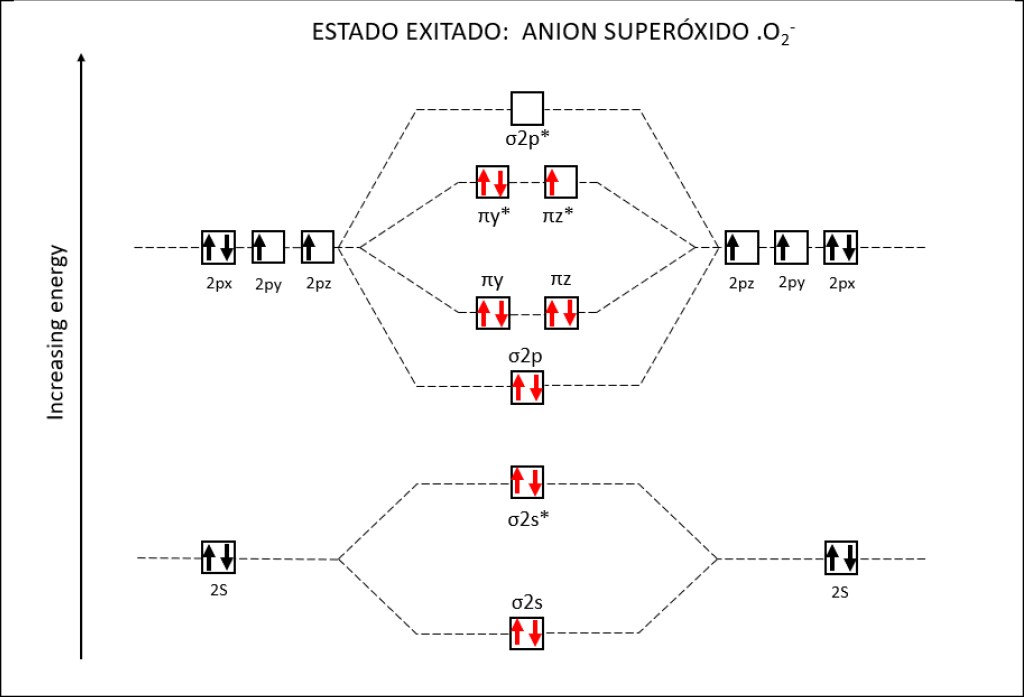
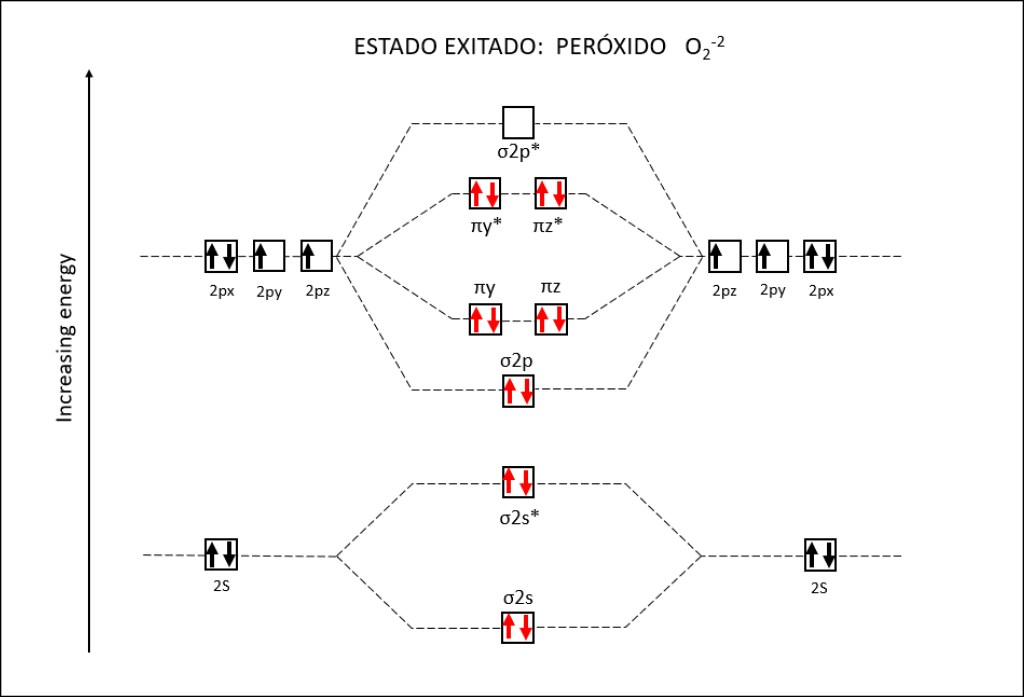
Bajo estas condiciónes, la probabilidad de generarse especies reactivas de oxígeno ROS, es muy alta, exponiendo a PSI y PSII a daños severos. La síntesis de especies reactivas del oxígeno y los orbitales moleculares correspondientes a las mismas se resumen en las Fig 1 y Fig 2.
Figura 1. Rutas de formación de especies reactivas de oxígeno.
Figura 2 : Orbitales moleculares correspondientes al estado ground y a los estados exitados superóxido y peróxido de la molécula de oxígeno.
La generación de radicales hydroxil se dá por dos vías principales:
Por acción de la luz UV , que disocia H2O2 a su forma 2 OH.
En presencia de Fe(II), en la reacción de Fenton:
Fe2+ + H2O2 → Fe3+ + OH. + OH–
Los radicales hydroxil son extremadamente reactivos, responsables del estrés oxidativo y causantes del daño no solo de los fotosistemas sino en general del entorno celular.
Mientras PSII tiene una capacidad de respuesta regenerativa relativamente alta ante la acción de especies reactivas, PSI es mucho más sensible a daños definitivos, exponiendo a la maquinaria global a colapsar en su función.
PROTECCIÓN ROS
La generación de especies reactivas de oxígeno hace necesario contar con rutas bioquimicas de control que permitan mantener el entorno fotosintético en estado oxidado, ver Fig 3.
Figura 3. Rutas NPQ y protección ROS presentes en la maquinaria fotosintética de cyanobacterias.
Las rutas de control ROS pueden clasificarse en dos tipos:
RUTAS PREVENTIVAS: Actúan sobre entornos reductores redireccionando el flujo de electrones hacia pool de quinonas para luego extraerlos por agentes oxidantes específicos.
RUTAS CORRECTIVAS: Actúan reduciendo las especies ROS generadas.
RUTAS PREVENTIVAS ROS
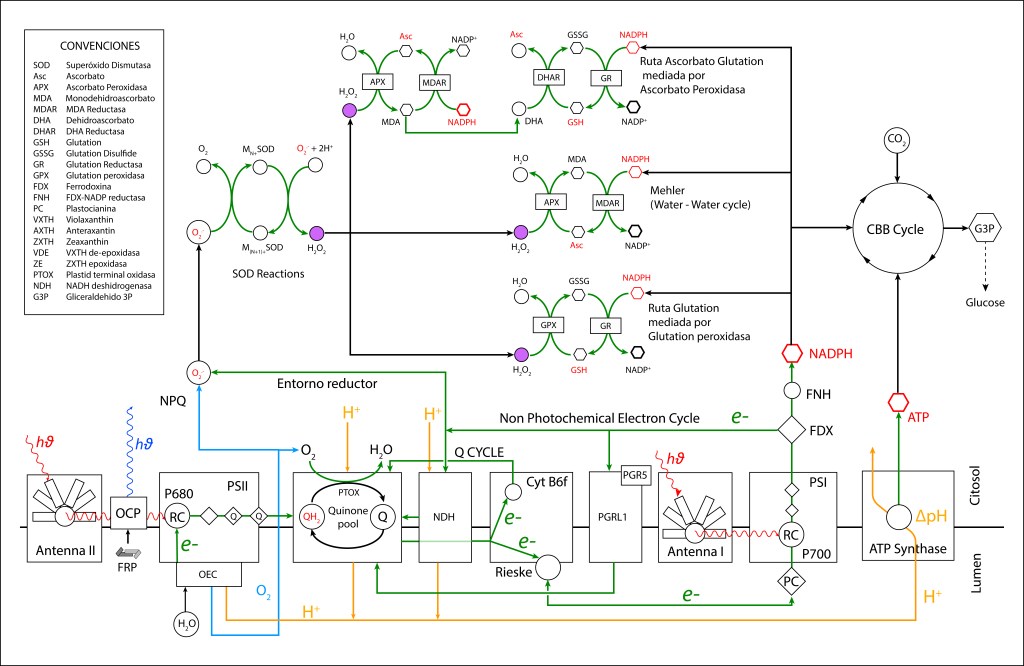
RUTA PTOX MEDIADA POR NDH-1
PTOX Deriva su nombre de la enzyma “Plastid Terminal Oxidase”, o“Plastoquinol Terminal Oxidase“, la cual reside adyacente a la membrana thylakoide.
Esta enzima actúa como válvula de seguridad, extrayendo electrones del pool de quinonas mediante la reacción
PQH2 + O2 → 2 PQ + 2 H2O
PQ es reducido a su forma PQH2 mediante un flujo cíclico de electrones (Non photochemical electron cycle) provenientes de FDX– siguendo la ruta
FDX– → NDH-1 → PQ → PQH2
NDH-1 corresponde al complejo proteico transmembrana NADPH dehydrogenasa presente en cyanobacterias, es responsable de la oxidación de FDX– y de la correspondiente reducción de PQ.
La transferencia de electrones en la ruta PTOX se conoce como “Clororespiración” y se puede resumir asi:
La ruta se activa, entre otras causas, cuando la disponibilidad de CO2 citoplasmatico no es lo suficientemente alta como para atender los requerimientos del ciclo de Calvin Benson. Bajo esta condición, la caída en concentración de CO2 desacelera el ritmo del ciclo CBB generando un represamiento de las especies NADPH y FDX– , lo que promueve un entorno reductor favorable a la formación de especies ROS, particularmente por FDX– , cuyo alto represamiento puede terminar transfiriendo electrones a O2 generado las especies ROS mencionadas.
Para prevenir esta condición, las rutas PTOX reenrutan los electrones hacia el pool de quinonas Se ha reportado que la acción de PTOX es responsable hasta del 30% del drenaje de electrones en el tráfico ETC (Zolotereva et.al. 2022).
La acción colaborativa PTOX/NDH-1 actúa sobre FDX– “aguas abajo” de PSI y Cyt b6f permitiendo que bajo condiciones de stress, la síntesis de ATP se mantenga intacta, lo que hace de este esquema de protección un mecanismo altamente eficiente para la función general fotosintética.
NDH-1 participa en el bombeo de protones al lumen durante la transferencia electrónica de manera equivalente al complejo I mitocondrial y al NDH presente en plantas y algas verdes, contribuyendo a incrementar la fuerza protomotriz ΔpH , lo que aumenta la eficiencia energética del sistema.
RUTA PTOX MEDIADA POR PGRL1-PGR5
La proteína transmembrana PGRL1 (Proton Gradient Regulation Like 1) es una proteína reguladora transmembrana de bajo peso molecular, presente en cyanobacterias, plantas y algas verdes.
PGRL1 actúa en conjunto con la proteina PGR5 (Proton Gradient Regulation 5), conformando un heterodímero con función equivalente a la de NDH-1.
La velocidad de respuesta del heterodímero ante variaciones en concentración FDX– es mucho mayor que la de NDH-1, lo que permite que las dos proteínas actúen de manera complementaria para el funcionamiento óptimo de PTOX. Adicionalmente, mientras PGRL1 opera en condiciones de alta intensidad lumínica, desempeñando una función fotoprotectora, NDH-1 se activa en condiciones de baja luminosidad o bajo stress prolongado.
En resumen, NDH-1 y PGRL1 actúan rediraccionando“de manera preventiva” el flujo de electrones de FDX– hacia el pool de quinonas generando un flujo cíclico electrónico no fotoquímico que contribuye a mantener en estado oxidado el entorno PSI , minimizando por esta vía la generación de especies ROS. Ambas rutas habilitan la función de drenaje PTOX, con H2O como depositario final de electrones y oxígeno provenientes del sistema.
RUTAS CORRECTIVAS ROS
Actúan reduciendo H2O2 a H2O mediante peroxidasas específicas, controlando los niveles ROS en citosol y membrana thylakoide.
Previa la activación de las rutas de control, radicales superóxido O.−2 deben ser convertidos en H2O2 y O2 mediante la acción de Superóxido dismutasas, SOD, en la siguiente reacción simplificada:
O.−2 + O.−2 + 2H+ → O2 + H2O2
SOD corresponde a una familia de metaloenzimas antioxidantes cruciales a la salud celular presentes en archaeas, bacterias y eukariotas que, dependiendo del metal o metales coordinados, se clasifican en los siguientes grupos:
FeSOD : Presente en citosol
MnSOD: Asociada en cyanobacterias y plantas a membrada thylakoide en vecindad a PSII
Cu/ZnSOD: Presente en citosol
NiSOD: presente en cytosol. (Exclusivo de prokariotas)
La reacción comprende dos etapas:
Etapa de reducción del metal coordinado, oxidando O.−2 a O2 :
M(n+1)+−SOD + O.−2 → Mn+−SOD + O2
Etapa de reoxidación del metal coordinado, reduciendo O−2 a H2O2 :
Mn+−SOD + O−2 + 2H+→ M(n+1)+−SOD + H2O2
El estado de oxidación del catión metálico evoluciona entre n+1 → n → n+1:
(Cu2+ → Cu+ → Cu2+)
(Mn3+ → Mn2+ → Mn3+)
(Fe3+ → Fe2+ → Fe3+)
(Ni3+ → Ni2+ → Ni3+)
Una vez convertido O−2 en H2O2 por SOD, tres rutas contribuyen al control ROS mediante la reducción de H2O2 a H2O, teniendo como factor común la cesión inicial de electrones a partir de NADPH.
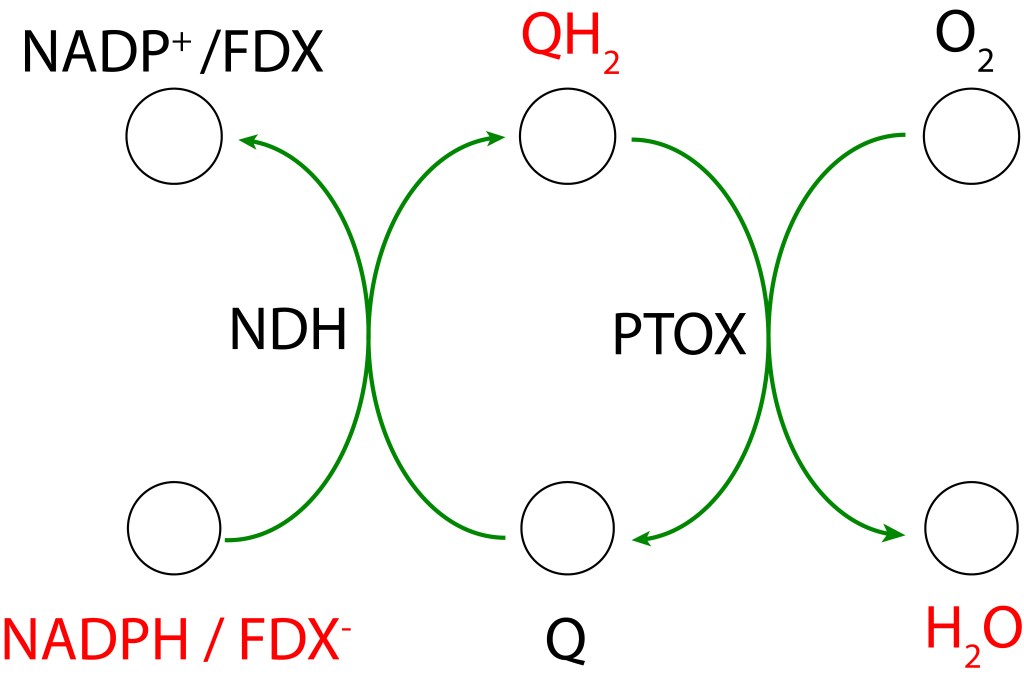
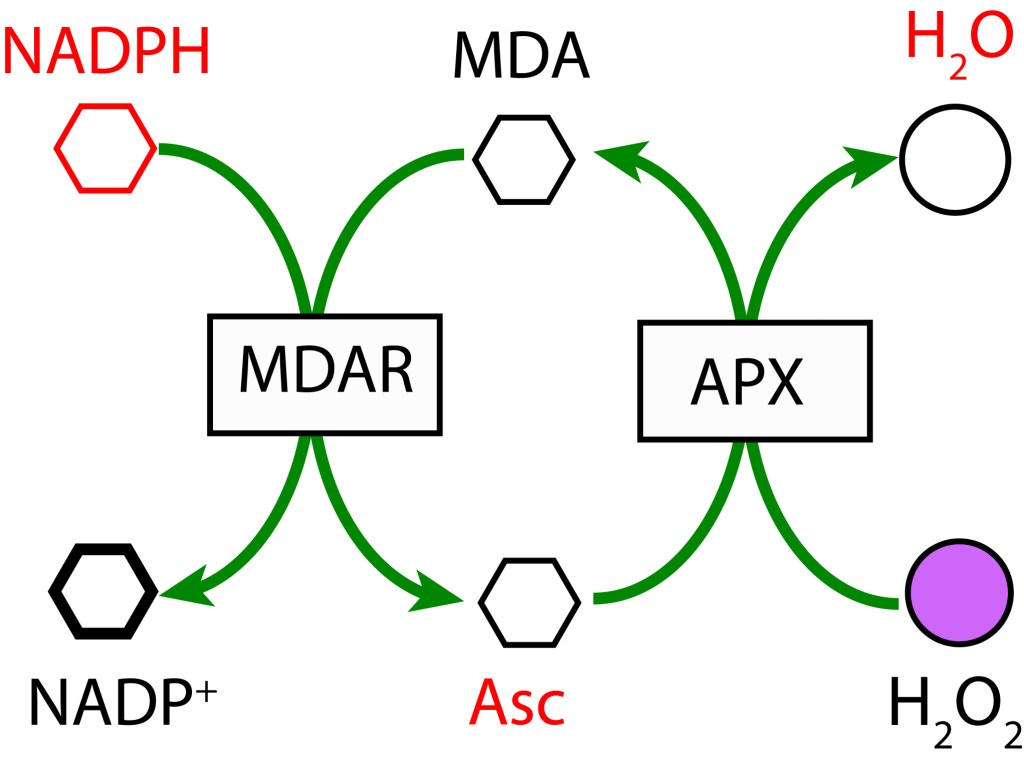
REACCIÓN DE MEHLER (CICLO AGUA-AGUA)
La reacción de Mehler, conocida también como ciclo agua-agua (WWC), está presente en todos los organismos con fotosíntesis oxigénica y presencia de fotosistema PSI.
En un primer paso, MDA (Monodeshidroascorbato) se reduce a Ascorbato (ASC) usando NADPH como donante de electrones mediante la enzima MDAR (MDA Reductasa). En la etapa final MDA se regenera mediante la enzima Ascorbato Peroxidasa y transferencia de electrones al Peróxido de Hidrógeno para formar agua.
Aunque el ciclo se conoce como ciclo Agua-Agua, referido a que la fuente primaria de los electrones es agua (proveniente del ciclo de KOK), y que el producto final de la ruta también es agua, esta condición es común para las tres rutas correctivas.
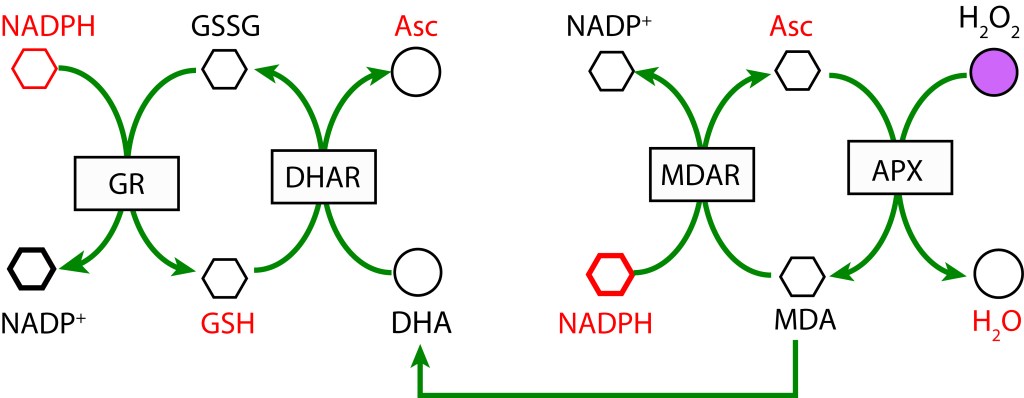
RUTA ASCORBATO GLUTATION MEDIADA POR ASCORBATO PEROXIDASA
La ruta es activada tras la reducción de MDA (Monodehidroascorbato) a Ascorbato utilizando la enzima MDAR (Monodehidroascorbato reductasa) con NADPH como donador de electrones. MDA es regenerado mediante la acción de la enzima Ascorbato peroxidasa (APX) resultando en la reducción de H2O2 a H2O. Como radical, si no se favorece una rápida reducción, MDA dismuta a Ascorbato y Dehidroascorbato (DHA) .
En una segunda cadena de oxidoreducción, Dehidroascorbato se reduce a Ascorbato mediante la enzima Dehidroascorbato reductasa (DHAR), utilizando Glutatión (GDH) como agente reductor, el cual se oxida a su forma Glutatión disulfido (GSSG). Finalmente, GSH se regenera con NADPH como donor de electrones y la acción de la enzima Glutatión reductasa (GR).
ROL DEL ASCORBATO
ASC (forma salina dedl ácido Ascórbico, o Viamina C), es el principal antioxidante de cyanobacterias y plantas superiores. En adición a su función durante la fotosíntesis, participa como señalizador durante el proceso de la mitosis, forma parte del control de la función meristemal, contribuye al crecimiento radicular en plantas e interviene en la activación de la floración y durante la senecencia vegetal.
Cuatro rutas de síntesis de Ascorbato han sido descritas en plantas, con D-Glucosa, Myo-Inositol y pectinas de la pared celular como precursoras.
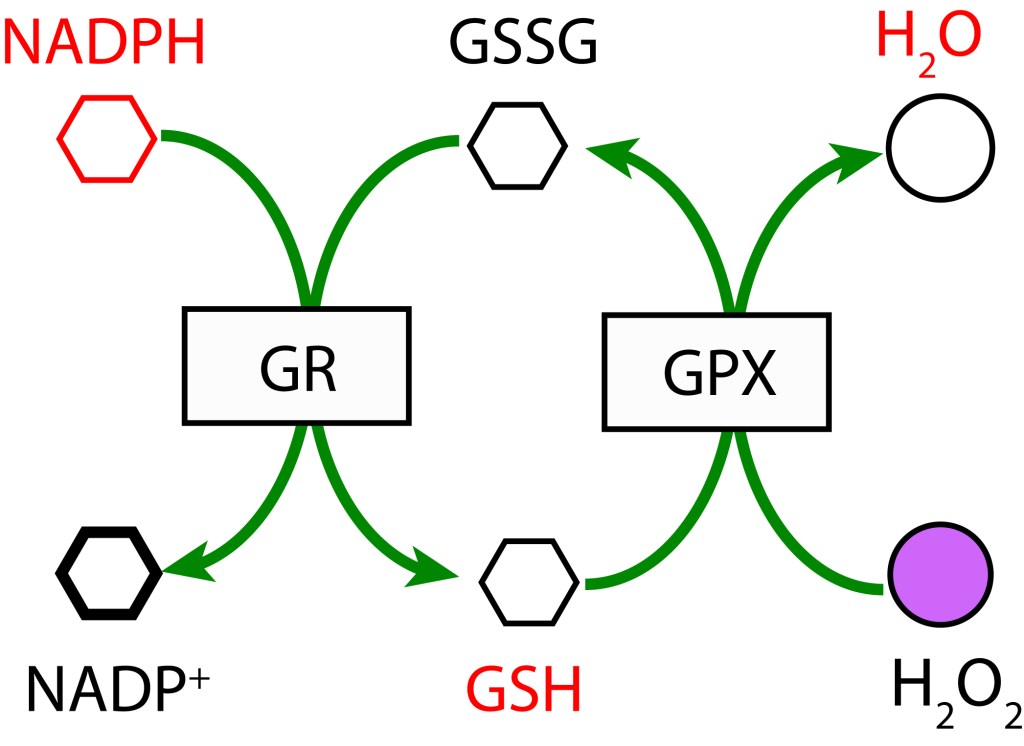
RUTA GLUTATION MEDIADA POR GLUTATION PEROXIDASA
En esta ruta, GSH participa como agente reductor actuando sobre H2O2 para producir H2O mediante la enzima Glutation Peroxidasa (GPX). GSH es regenerado a partir GSSG con NADPH como donor de electrones bajo la acción de la enzima Glutatión Reductasa (GR).
NPQ (NON PHOTOCHEMICAL QUENCHING)
Las rutas de protección expuestas previamente corresponden a protección electrónica de alta energía, presente en especies reactivas ROS.
Existe adicionalmente una ruta de protección fotónica equivalente en función al ciclo de Xantophyllas propia de plantas superiores, destinada a disipar excesos de luz y calor en lo que se denomina Non-Photochemical Quenching” (NPQ), (Extinción No Fotoquímica), operando entre el nucleo del phycobilisoma y el centro de reacción RC impidiendo que fotones de alta energía degraden el fotosistema.
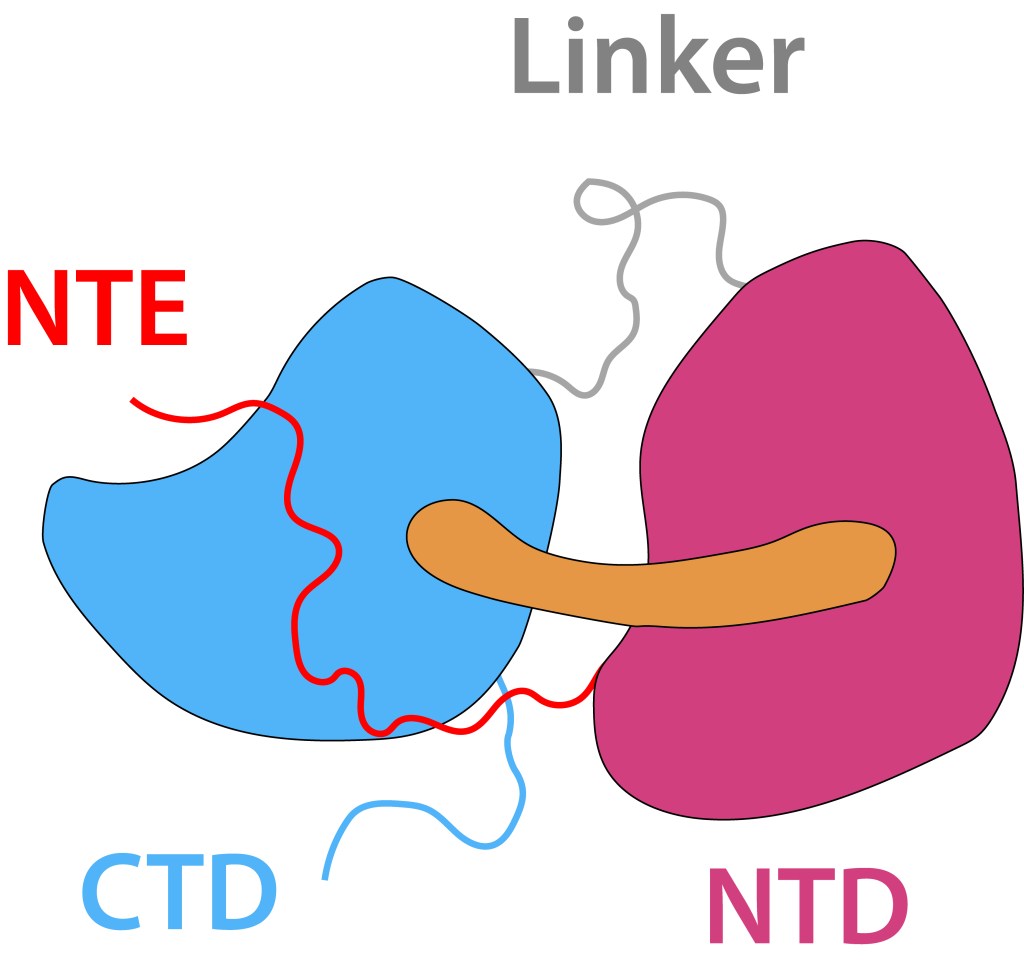
El core del sistema es la “Proteina Carotenoide Naranja”, “OCP”, ver Fig 4, molécula soluble en agua con un peso molecular de 35 kDa, dos dominios, C-Terminal (CTD) y N-terminal (NTD), separados por un linker que actúa a manera de bisagra entre los dominios, una terminal N extendida (NTE) contribuyendo a mantener CTD y NTD adyacentes en estado ground (OCPO) y un cofactor keto-carotenoide (Canthaxanthina).
Figura 4. Orange Carotene Proteine (OCP). Elementos principales
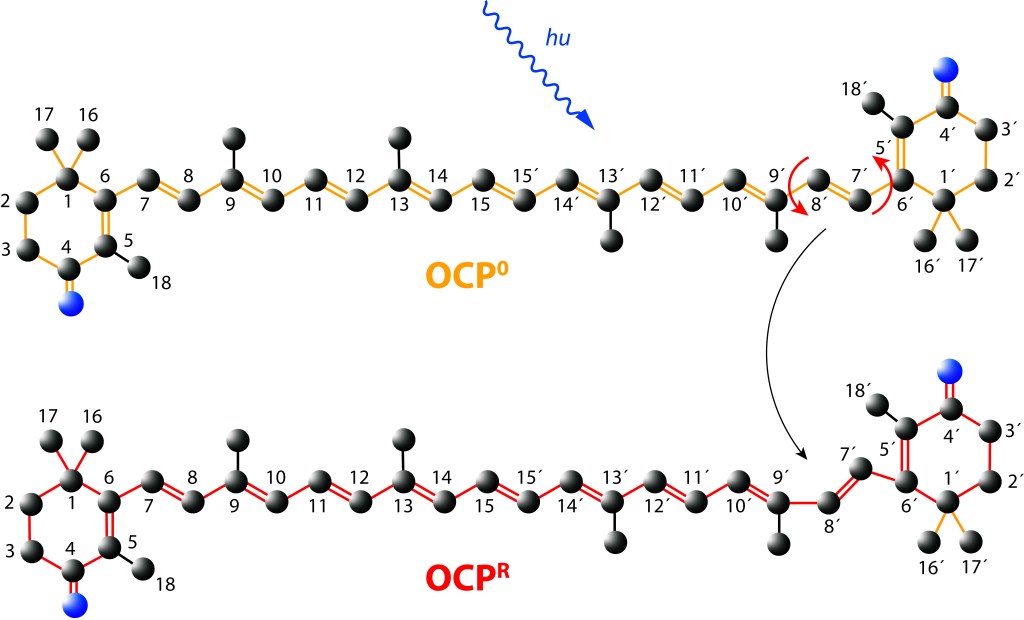
Ante la exposición a luz de alta energía, el cofactor Caanthaxanthina sufre cambios reversibles en su estructura molecular espacial, ver Fig. 5, con alteraciones en la absorción/emisión lumínica, pasando de naranja (ground) a roja en estado activado, loque define dos estados: OCP0 → OCPR.
Figura 5. Canthaxantica en estado Ground (OCP0) y estado exitado (OCPR)
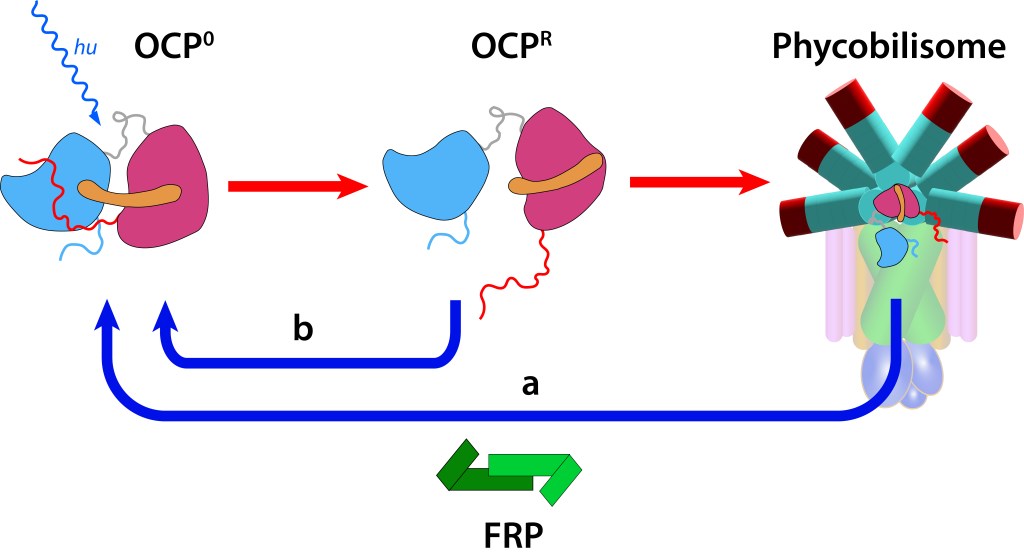
Estos cambios generan a su vez alteraciones reversibles en OCP, ver Fig 5., incluyendo translocación del caroteno hacia el domino NTD y separación de los dominios N-terminal y C-terminal ver Fig.6.
Figura 6. Estructura y función OCP. (Modificado de Maksimov et.al, 2017).
En este estado OCPR actúa a nivel del nucleo del phycobilisoma impidiendo que alta energía se transmita hacia el centro de reacción, protegiendo de esta manera al fotosistema (fotoprotección NPQ).
Si la protección del fotosistema no es requerida, la proteina retorna a estado OCP0 mediante la acción del dímero FRP (Fluorescence Recovery Protein), lo que permite la reactivación de la función fotosintética.
BIBLIOGRAFÍA
Zolotereva, E., Polishuk,O. Chlororespiration as a Protective Stress-inducible Electron Transport Pathway in Chloroplasts. The Open Agriculture Journal • 14 Oct 2022
Slonimskiy, Y.B., Maksimov, E.G. & Sluchanko, N.N. Fluorescence recovery protein: a powerful yet underexplored regulator of photoprotection in cyanobacteria†. Photochem Photobiol Sci19, 763–775 (2020). https://doi.org/10.1039/d0pp00015a
Maksimov EG, Sluchanko NN, Slonimskiy YB, Mironov KS, Klementiev KE, Moldenhauer M, Friedrich T, Los DA, Paschenko VZ, Rubin AB. The Unique Protein-to-Protein Carotenoid Transfer Mechanism. Biophys J. 2017 Jul 25;113(2):402-414. doi: 10.1016/j.bpj.2017.06.002. PMID: 28746851; PMCID: PMC5529199.
Pagels, F.; Vasconcelos, V.; Guedes, A.C. Carotenoids from Cyanobacteria: Biotechnological Potential and Optimization Strategies. Biomolecules 2021, 11, 735. https:// doi.org/10.3390/biom11050735
Chukhutsina, V.U., Baxter, J.M., Fadini, A. et al. Light activation of Orange Carotenoid Protein reveals bicycle-pedal single-bond isomerization. Nat Commun13, 6420 (2022). https://doi.org/10.1038/s41467-022-34137-4
La presente lectura sobre cyanobacterias es el punto de convergencia de todas las lecturas previamente desarrolladas sobre el fenómeno de la fotosíntesis, pues este grupo bacteriano fué hace 2,500 millones de años punto de convergencia de evolución Marguliana, como también punto de divergencia Darwinista, lo que definió la impronta de la vida en nuestro planeta.
A las cyanobacterias se le debe la atmósfera planetaria rica en oxígeno, su color azul visible desde el espacio, las bandas rojas de hierro Fe3+ (Hematita Fe2O3) y Fe2+/Fe3+ (magnetita), huella geológica de su actividad bioquímica, como también la eucariogénesis y la evolución de las plantas y en último término de los animales pluricelulares, de manera que la especie humana no existiría si hace 2,500 millones de años no hubieran dominado, como dominaron, estas revolucionarias bacterias fotosintéticas.
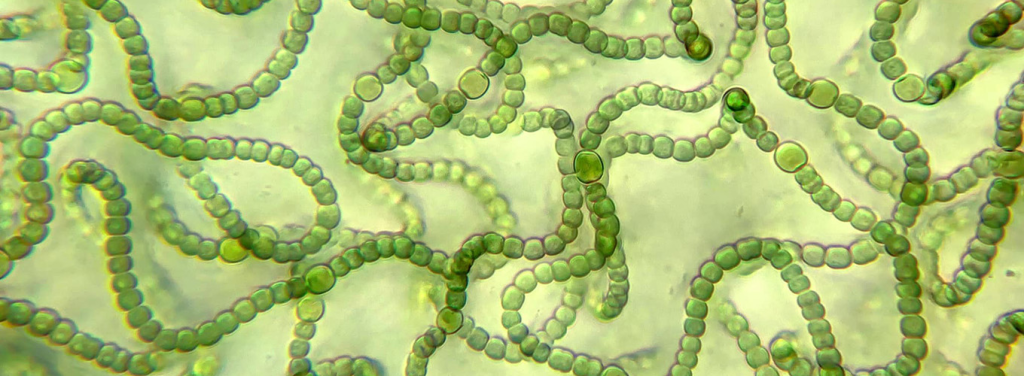
Las Cyanobacterias son un grupo de bacterias Gram-negativas (Phyllum Cyanobacteriota) caracterizadas por realizar fotosíntesis oxigénica mediante un complejo bioquímico dual PSII-PSI, lo que las diferencia de los demás grupos fotosintéticos bacterianos, donde PSII o PSI están presentes, pero nunca operando a la vez, ver fig 1.
El complejo fotosintético se localiza en invaginaciones intracelulares de la membrana plasmática denominadas membranas Thylakoides, precursoras de las estructuras thylakoidales propias de los cloroplastos presentes en las células del reino vegetal.
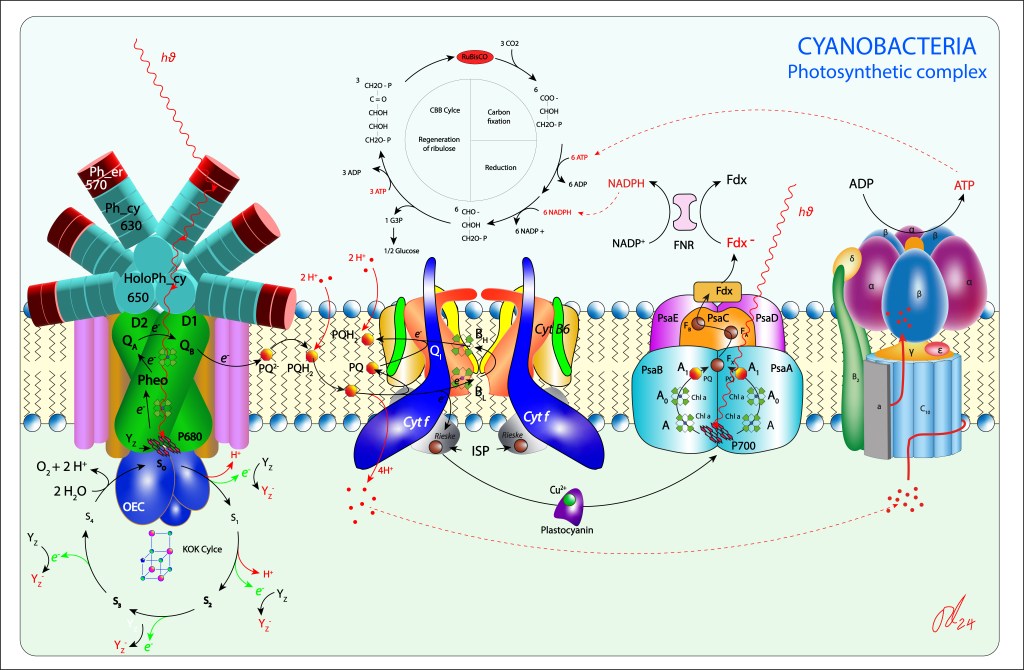
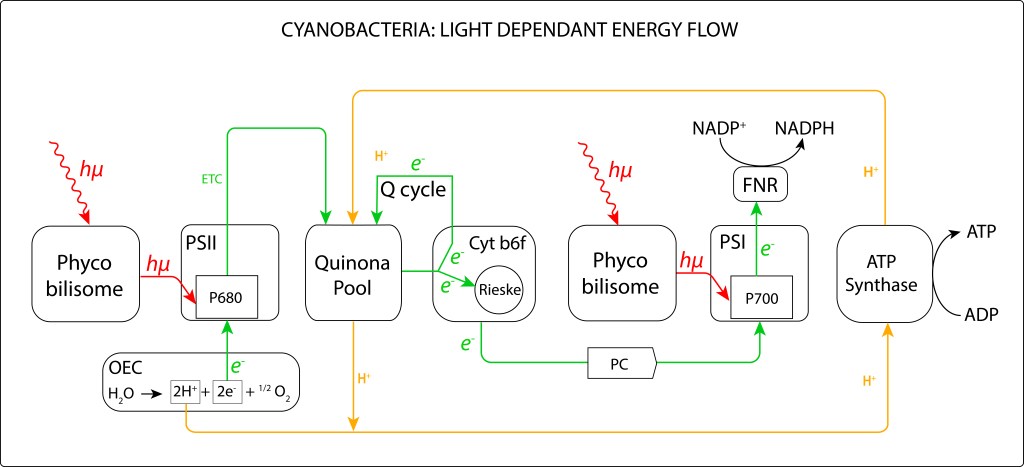
Figura 1. Complejo fotosintético de Cyanobacterias
La maquinaria fotosintétic de las cyanobacterias comprende los siguientes subsistemas:
Complejo antena (Light Harvest Complex) denominados phycobilisomas, los cuales están intimamente ligados a los fotosistemas PSII y PSI
Fotosistemas PSII y PSI propiamente dichos, encargados el primero de reducir quinonas y el segundo reducir NADH
Citocromo b6f, transportador de electrones hacia PSI y responsable de la generación del potencial protónico PMF
Centro OEC (Oxigen Evolving Center) responsable de la oxidación del agua.
ATP Synthase, que, aunque no forma parte del complejo, es fundamental para la síntesis de ATP
A continuación un resumen general de los diferentes componentes de la maquinaria:
PHYCOBILISOMA (PBS)
Durante el proceso de la fotosíntesis, la energía lumínica es capturada por complejos antena denominados Phycobilisomas (PBS). La energía es luego transmitida hacia los centros de reacción (RC), donde pares especiales de clorofilas Chla son exitados a niveles energéticos que permiten la liberación electrónica en Chla para iniciar la cadena de transporte de electrones (ETC) , motor final de las maquinarias fotosintéticas.
Cada Phycobilisoma está compuesto por seis (raramente ocho) estructuras proteicas de corte cilíndrico en disposición radial, ver Fig 2., convergiendo hacia un nucleo proteico central.
Figura 2. Phycobilisoma. A: Vista general. Se incluye con propósito ilustrativo en tonos suaves el centro de reacción. B: Detalle estructural. C: Disposición de subunidades en los trímeros.
RADIOS:
Cada radio a su vez está conformado por 2 – 6 discos de phycobiliproteinas (10-12 nm de diámetro), los cuales actúan como unidades de captura y transferencia de energía lumínica hacia el nucleo del complejo. Los discos, de estructura trimeral, pueden operar de manera individual, trímeros (αβ)3 , o por parejas enlazadas por proteinas linker, en cuyo caso su estructura es hexameral (αβ)₆, ver Fig 2b y 2c. El rol de la proteina linker no es solamente enlazante, también contribuye a ajustar los niveles energéticos y a dirigir la energía hacia el nucleo del complejo antena.
De distal a proximal, y dependiendo de los cromóforos que contienen, las proteinas de los radios se clasifican en:
PHYCOERITHRINAS (PE) → Colectores primarios de luz .
PHYCOCYANINAS (PC) → Transfieren la energía colectada por PE hacia el nucleo del phycobilisoma.
La estructura de los radios puede variar acomodandose a la disponibilidad de energía. Así, PE puede estar ausente, en cuyo caso el colector primario es PC. De manera similar, PC puede faltar, y en ese caso PE comunica directamente con los cromóforos del nucleo.
NÚCLEO
El núcleo está conformado por 2-3 cilindros dispuestos horizontalmente, ver Fig.2a, con 6-9 discos αβ3 por cilindro, agrupados por parejas mediante proteinas linker, resultando en estructuras αβ₆.
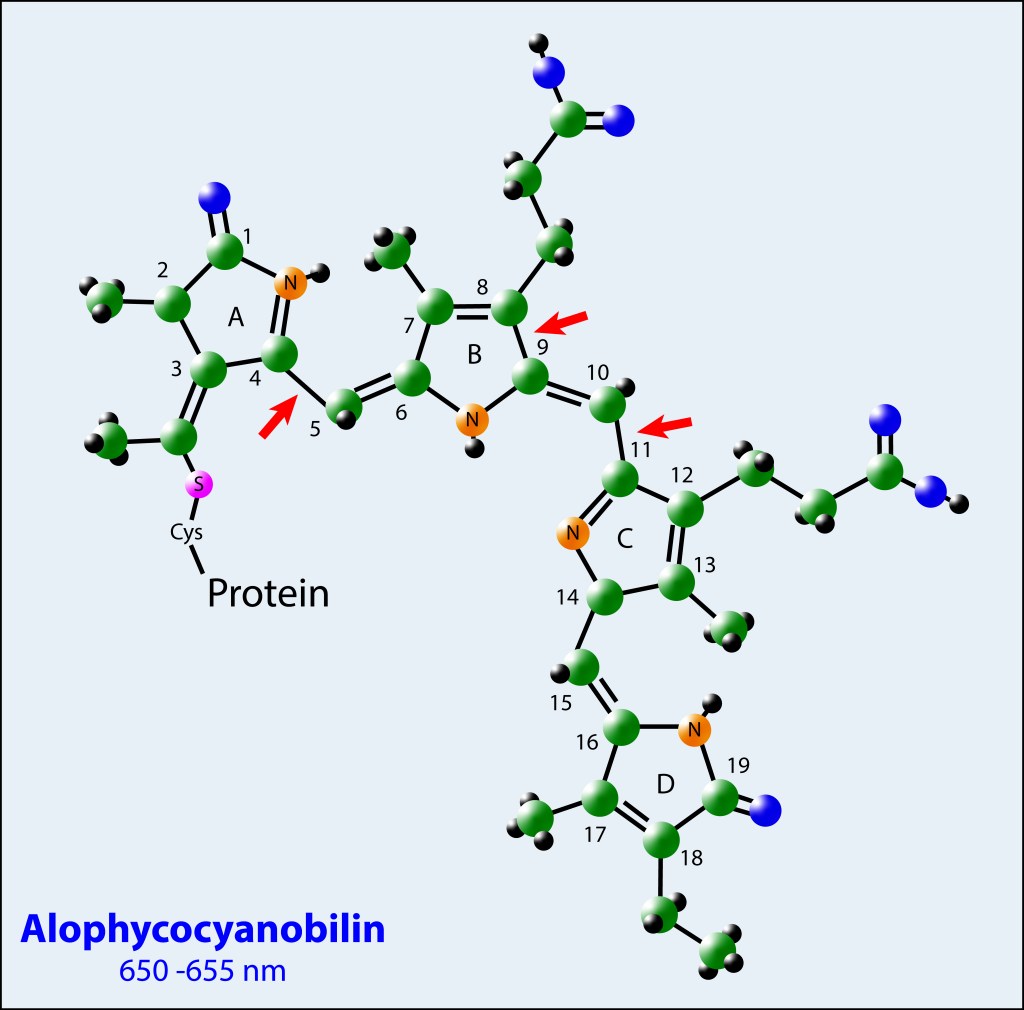
La proteina del nucleo corresponde a ALOPHYCOCYANINA (APC), derivando su nombre del pigmento correspondiente, Alophycocyanobilina, el cual es exitado por los cromóforos radiales que actúan a modo de embudo energético. Este pigmento es el responsable de la exitación del par especial de clorofilas localizada en el centros de reaccion.
El núcleo tiene en consecuencia una función conectora entre el complejo antena y el centro de reacción RC, de manera análoga a la capa FMO de los clorosomas propios de las baterias verdes del azufre (ver lectura correspondiente), si bién presentan diferencias significativas:
El núcleo del ficobilisoma es una estructura grande, modular y con alta plasticidad morfológica, adaptable en número de discos y organización de los mismos dependiendo de las condiciones lumínicas, mientras que FMO es un complejo pequeño,rígido en estructura, no adaptable a fluctuaciones de las condiciones ambientales.
El cromóforo contiene Aloficocianina, conecta con el par especial Chla en RC P680 de (PSII y P700 de PSI), mientras que FMO contiene Bacterioclorofila y transmite la energía al par Bchla P840 en RC.
El phycobilisoma requiere para su exitación de una intensidad de luz mucho mayor que el chlorosoma, lo que define y diferencia los nichos ecológicos ocupados por ambos grupos biológicos.
El número de pigmentos presentes en el phycobilisoma es muchísimo menor que el del chlorosoma (decenas en el ficobilisoma, cientos de miles e el corosoma).
Los pigmentos del phycobilisoma requieren proteinas estructurantes donde se anclan y organizan, mientras que la organización y distribución de pigmentos en el chlorosoma obedece a una estructura semicristalina auto-organizada, y salvo la envoltura que los contiene y la unidad conectora (FMO), hay ausencia proteínica al interior del complejo antena.
El phycobilisoma es típico de linajes oxigénicos evolutivamente recientes, mientras que el chlorosoma es típico de fototrofía anoxigénica mucho mas antigua.
PIGMENTOS FOTOSINTÉTICOS
Para que la energía fluya desde el Phycobilisoma hasta PSII/PSI mediante transferencia no radiativa FRET se requiere cumplir un conjunto de condiciones:
Energías de exitación decrementales en el sentido del flujo ETC
Distancias reducidas entre cromóforos adyacentes
Superposición espectral entre las frecuencias de emisión y frecuencias de exitación de pigmentos en la cadena
Orientación favorable a FRET entre los dipolos
Adecuada vida media de estados exitados
Las proteínas PE, PC y APC contienen los pigmentos de los tipos Phycoerytrobilina, Phycocyanobilina y Alophycocyanobilina respectivamente, cuyas energías de exitación/emisión cumplen las condiciones descritas, lo cual garantiza el flujo de energía en la secuencia
PE → PC → APC → PSII/PSI
El flujo de energía y la tabla de valores de exitación/emisión en el phycobilisoma se ilustran en la Fig 3.
Figura 3. Flujo de energía y valores de absorción/emisión correspondientes a las etapas de flujo de energía en el phycobilisoma
Los pigmentos fotosintéticos obedecen a una estructura tetrapirrólica de anillo abierto, con diferencias en el radical asociado al carbono 18 (Vinil para Phycoerytrobilina, Ethil para Phicocyanobilina y Alophycocyanobilina), y con diferencias en las posiciones de algunos enlaces Pi conjugados entre Phycocyanobilina y Alophycocyanobilina , ver Fig.4.
Estas diferencias moleculares, combinadas con las cargas eléctricas de los aminoácidos que las rodean, definen las energías de absorción/ emisión para cada tipo de pigmento.
Para los tres casos, los pigmentos están anclados a las proteínas vía residuos Cisteína mediante enlaces covalentes Tioéter.
Figura 4. Estructura molecular de los pigmentos involucrados en el phycobilisoma
FOTOSISTEMA PSII
La energía capturada y transmitida desde los pigmentos de las radios hasta el nucleo del complejo es transmitida al par especial de clorofilas localizado en la base del fotosistema PSII, el cual es un complejo de proteínas transmembrana en un arreglo heterodimérico D2-D1, ver Fig.5.
El acoplamiento entre los pigmentos del nucleo y el par especial de clorofilas es mucho mas fuerte y mucho más coherente que el acoplamiento entre pigmentos al interior del phycobilisoma, lo que lo define como un caso extremo de resonancia de Förster, renombrado recientemente como EET (Exitation Energy Transfer)
Figura 5. Fotosistema PSII. Estructura y cadena de transporte ETC.
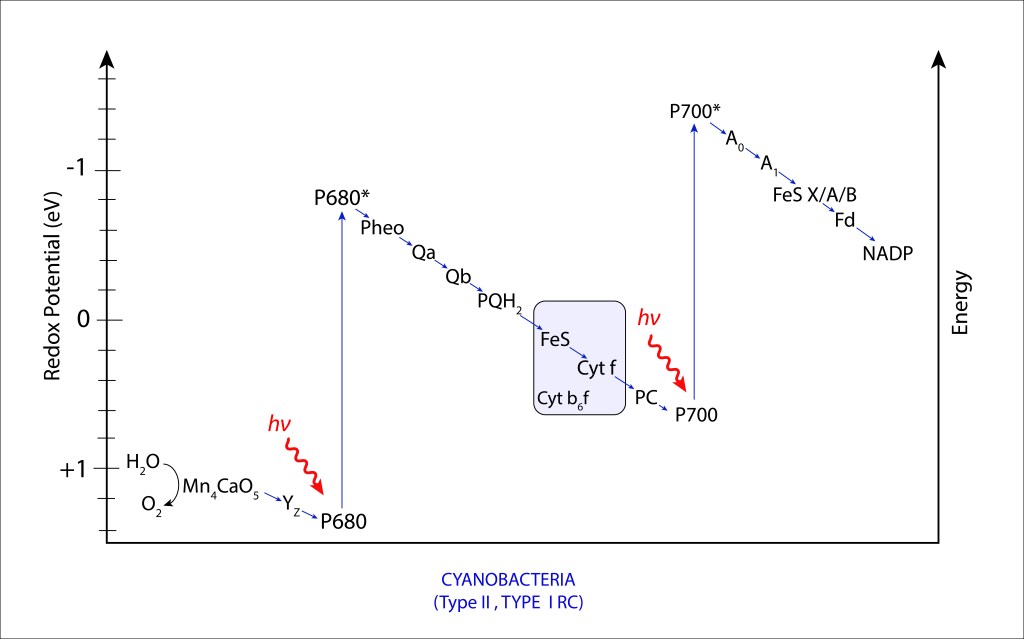
Mediante EET, la energía procedente del complejo antena exita el par especial de clorofilas P680 llevandolo a su forma P680*, elevando su potencial redox de
+ 1,2 → -0,9 eV
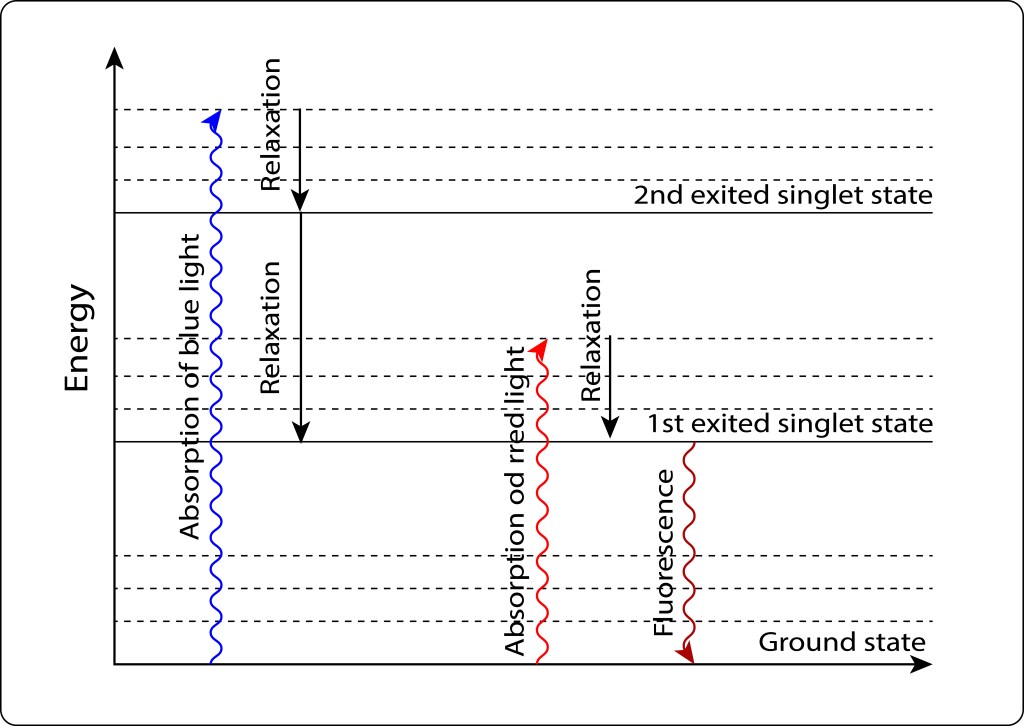
Si los requerimientos energéticos celulares son bajos, el par especial retorna al estado Ground mediante fluorescencia, ver Fig 6.
Figura 6. Exitación/relajación electrónica en pigmentos fotosintéticos
Ante demanda energética, el electrón exitado π* (procedente de la cadena de enlaces conjugados), no retorna a ground sino que se libera oxidando el par especial de clorofilas Chla , iniciando una cadena de transporte de electrones ETC, que en su primera fase (PSII) sigue la ruta ETC
P680* → Pheophytin → Quinone A → Quinonne B → Plastoquinol
El pigmento Phaeophitin corresponde estructuralmente a una molécula de clorofila Chla sin presencia del átomo central de magnesio coordinado. Las quinonas corresponden a Plastoquinonas, muy estables en ambientes ricos en oxígeno.
Para reducirse completamente, las plastoquinonas PQA y PQB requieren dos electrones, de manera que el ciclo de exitación y liberación electrónica del par especial de clorofilas debe repetirse dos veces, y previamente dos fotones deben ser capturados y transmitidos a RC secuencialmente por parte del complejo antena.
Una vez completamente reducida, PQB2- captura dos protones procedentes del citoplasma adquiriendo la forma de Plastoquinol PQH2 :
PQB → PQB∙− → PQB2- → PQH2
Mientras que PQA está ligada fuértemente a PSII, PQB es fácilmente liberada en su forma plasoquinol, migrando a un reservorio especial de quinonas localizado en el espacio intramembrana thylakoidal denominado pool de quinonas, ver Fig 7.
Figura 7. Diagrama de flujo de energía en el complejo fotosintético de Cyanobacterias, reacciones dependientes de luz.
Para que la cadena de transporte ETC siga una dirección “cuesta abajo” desde P680* hasta PQH2 en PSII, (y más adelante hacia el pool de quinonas y finalmente hasta P700 en PSI), los “eslabones” de la cadena de transporte deben estar acoplados de modo que sus potenciales redox vayan disminuyendo paso a paso, ver Fig.8.
El tránsito de electrones a lo largo del proceso, al igual que en los complejos fotosintéticos presentes en los demás grupos bacterianos y en la maquinaria de foforilación oxidativa mitocondrial, permite generar un gradiente protónico intermembrana (PMF) indispensable para la síntesis de ATP.
Figura 8. Diagrama Z en el complejo fotosintético PSII/PSI de Cyanobacterias.
El transito de electrones descrito en la fig. 8 se conoce como ESQUEMA Z, que en resumen describe la forma en “Z” del transporte no cíclico de electrones durante las reacciones dependientes de la luz en la fotosíntesis de cyanobacterias y plantas superiores.
El Esquema “Z” comprende dos fases, correspondientes a PSII y PSI respectivameente. PSI maneja niveles energéticos mayores que PSII, lo que define para PSII un alto poder oxidante y para PSI un alto poder reductor, convirtiendo al sistema combinado en una maquinaria altamente oxidante, altamente reductora, que en la práctica se traduce en capacidad de oxidar H2O y capacidad de reducir NADP+ de manera directa. Comparativamente, maquinarias de un solo fotosistema, como las presentes en bacterias púrpura y bacterias verdes del azufre, la eficiencia fotosintética general está limitada. En las primeras, el débil poder reductor impide la síntesis directa de NADPH, teniento que invertir valioso ATP en su producción, mientras que en bacterias verdes del azufre ocurre lo contrario. Se habilita la síntesis directa de NADPH pero el bajo poder oxidante impide la utilización de H2O como fuente de electrones, ver Fig 9.
Figura 9. Centros de reacción de Bacterias púrpura y verdes del azufre
Hace algo cercano a 2,500 millones de años, sea por endosimbiosis seriada entre linajes de bacterias con maquinarias complementarias tipo I y tipo II, sea por adquisición de un segundo fotosistema por evolución propia , o sea por transferencia genética horizontal entre linajes, en lo que podría ser una especie de endosimbiosis bioquímica, de alguna manera dos maquinarias fotosintéticas se combinaron resultando en una máquina dotada de un “carburador de doble venturi” capaz de oxidar el agua, lo que marcó un punto de no retorno en la vida del planeta.
La utilización de agua como fuente de electrones en éste novedoso proceso fotosintético ha sido de lejos la más importante y trascendental innovación evolutiva alcanzada en el planeta. El nuevo recurso eliminó la dependencia de electrones procedentes de fuentes de limitado acceso (H2S, moléculas orgánicas, etc) permitiendo que las cyanobacterias pudieran ocupar todos los rincones del planeta donde hubiera agua líquida, convirtiendose así en el grupo más exitoso y de lejos más dominante que haya existido hasta la fecha .
Pero esta dominancia tuvo su lado obscuro, pués también fué la responsable de alterar profundamente la atmósfera primigenia, rica en dióxido de carbono y metano, por una atmósfera de oxígeno, lo que amenazó seriamente las formas de vida anoxigénica que prosperaban en ese entonces .
POOL DE QUINONAS
Como se mencionó anteriormente, el pool de quinonas es un depósito de quinonas oxidadas y reducidas ubicada en el espacio intramembrana tylakoidal, adyacente a los complejos fotosintéticos PSII, PSI y al Cyt b6f.
La naturaleza hidrofóbica de las quinonas permite que éstas permanezcan confinadas en dicho espacio, repelidas por los radicales fosfato de la capa bifosfolipídica.
La proporción y concentraciones de las formas PQ / PQH2 es dinámica y depende de los requerimientos fisiológicos, siendo PQH2 la portadora de energía desde PSII hacia en citocromo b6f.
CITOCROMO b6f
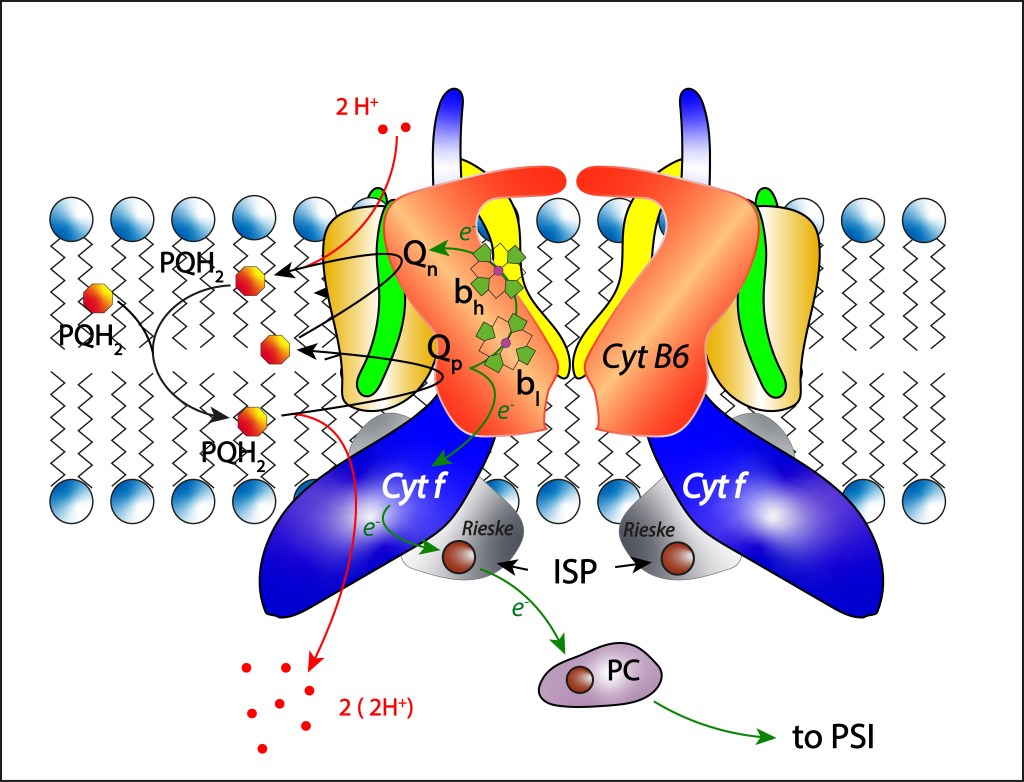
El complejo Cyt b6f es un complejo proteínico transmembrana con moléculas Heme como cofactores, ver Fig 10. Sus funciones consisten en transferir electrones al fotosistema PSI orientados a síntesis de NADPH y mover protones del citoplasma al lumen thylakoide mediante una secuencia de oxidaciones y reducciones de quinonas aprovechando una cadena de transporte de electrones ETC habilitada por cambios reversibles entre los estados de oxidación Fe³⁺ / Fe²⁺ de átomos de hierro presentes en moléculas Heme al interior del complejo.
Fig 10. Estructura del citocromo Cytb6f, y dinámica de transporte de electrones ETC.
La subunidad Cyt B6 tiene dos sitios activos, Qp oxidante y Qn reductor, responsables de alojar las quinonas a oxidar y reducir, respectivamente.
Del pool de quinonas es transladada una molécula PQH2 a Qp donde es oxidada a su forma PQ. Dos protones y dos electrones son liberados en la reacción. Los protones migran al lumen htilakoide donde contribuyen a incrementar la fuerza protomotriz PMF que luego se utilizará pra la síntesis de ATP.
En cuanto a los electrones, tienen dos destinos diferentes:
El primer electrón es capturado por el complejo 2Fe2S, cofactor de la proteína Rieske (Iron Sulfur Protein ISP) quien a su vez reduce una cuproproteina móvil presentee e el lúmen thylakoide denominada Plastocianina, responsable final de la transferencia de electrones desde Cyt b6f hasta PSI siguiendo la ruta
Qp → Cytf → [2Fe2S] → PC → P700–
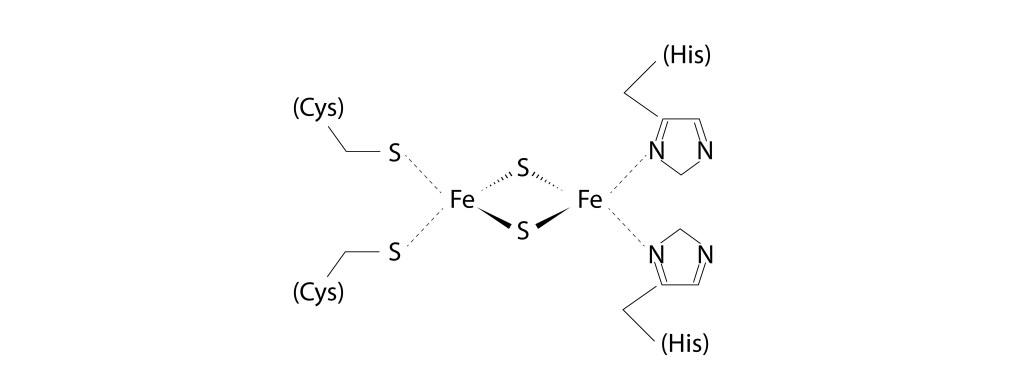
En cuanto a Rieske, el centro [2Fe2S] está coordinado por dos histidinas y dos cisteínas, en lugar de las cuatro Cystinas que caracterizan a la ferredoxina [2Fe2S], ver Fig 11.
Fig 11. Centro [2Fe-2S] presente en la proteina Rieske
Respecto a la Plastocianina (PC), se trata de una proteína móvil transportadora de electrones con un átomo de cobre como cofactor anclado a la proteina mediante cuatro ligandos: Imidazol de dos residuos histidina (His37, His87) , thiolato de Cys84 y thioether de Met92, lo que le confiere una estructura de tetrahedro irregular. Durante el proceso el cobre es reducido de la forma
Cu²⁺ → Cu⁺
En estado reducido, PC migra en el lumen hasta el PSI, donde dona el electrón a P700⁺, volviendo a su forma oxidada Cu²⁺.
Respecto al segundo electrón, este sigue la ruta
bl → bh (o bl → cn) → PQ
mediante cambios en los estados de oxidación Fe3+ – Fe2+ de los Heme correspondientes, para finalmente reducir parcialmente una plastoquinona PQ localizada en el sitio Qn .
Son necesarios dos ciclos como el descrito arriba para reducir completamnte la plastoquiuinona PQ localizada en Qn.
Una vez totalmente reducida, la plastoquinona incorpora dos protones procedentes del citoplasma a su estructura, retornando luego al pool de quinonas en su forma PQH2 .
Completados los dos ciclos, cuatro protones son transladados del citoplasma al lumen tylakoidal.
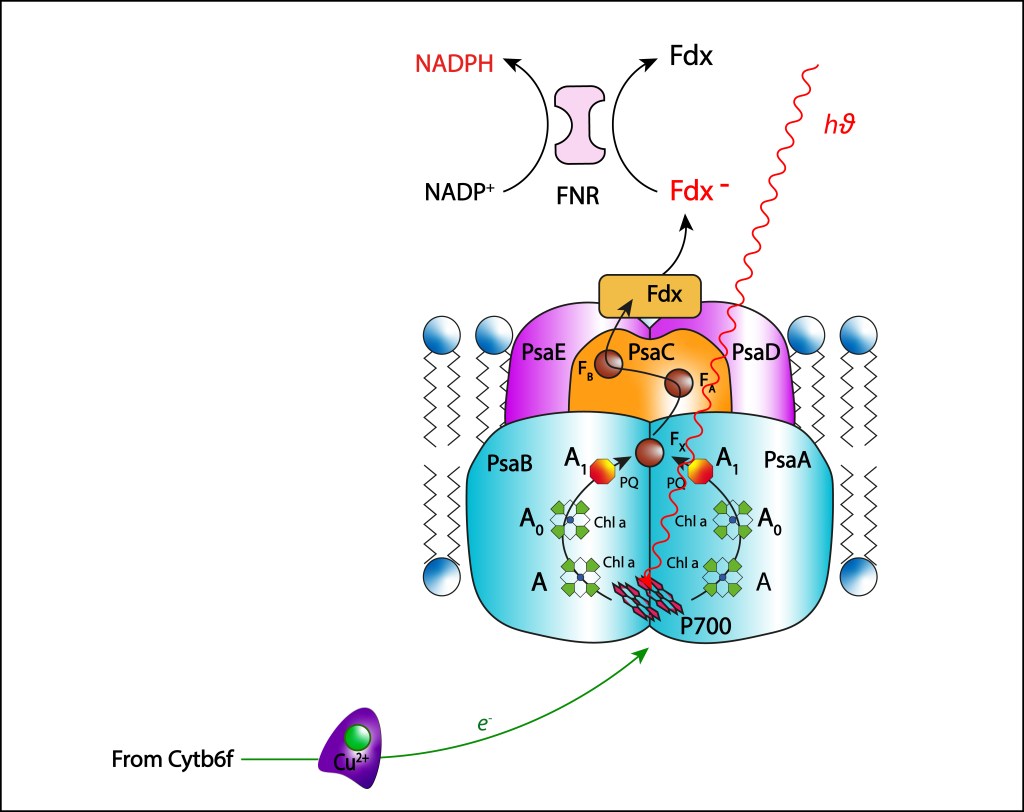
FOTOSISTEMA PSI
El fotosistema PSI es el último complejo involucrado en la cadena de transporte de electrones, su función es reducir NADP+ a partir de la oxidación del átomo de cobre precente en PC, por lo cual se conoce atmbién como Plastocianina-NADP Oxidoreductasa., ver Fig 12.
Figura 12. Fotosistema PSI. Estructura y cadena de transporte ETC
Como en el caso de PSII, complejos antena tipo phycobilisomas son responsables de transferir la energíalumínica al par especial de clorofilas, en este caso al dímero P700, con la energía necesaria para que un electrón sea liberado del par especial iniciando la cadena de transporte correspondiente.
Una vez liberado el electrón, el par especial adquiere el potencial oxidante necesario para oxidar la plastocianina PC procedente del complejo Rieske, retornando el par especial a su estado Ground, cambiando el estado de oxidación del átomo de cobre:
Cu⁺ → Cu2⁺
Dos ramas simétricas de cofactores están presentes en PSI. Las ramas parten de P700 al interior de las subunidades PSaB y PSaA, cada una conteniendo una molécula accessoria de Chla ( A), una segunda monomérica Chla ( A0) y una filoquinona (A1). Las dos ramas convergen en un cluster [4Fe-4S] central (Fx), ver Fig 13, apuntando hacia el citoplasma.
A pesar de existir dos ramas paralelas de cofactores A-Ao-A1, solo una es responsable de la cadena de transporte de electrones, usualmente la rama localizada en PSaA, mientras que la segunda rama, presente en PSaB , permanece inactiva.
De Fx la energía es transferida hacia dos cluster [4Fe-4S] denominados FA y FB localizados en la subunidad proteínica PsaC, para finalmente reducir una ferredoxina 2Fe-2S Fe-S , denominada Fdx, localizada en el citoplasma.
La ferredoxina requere dos electrones para reducirse completamente, de modo que dos ciclos secuenciales PC-Ferredoxina deben ser completados.
Éste agente reductor no transfiere directamente electrones a NADP+ , requiriendo una enzima intermediaria denominada ferredoxina-NADP+ reductasa (FNR). La transferencia de electrones se realiza en dos pasos:
FNR → Flavin-Semiquinona → FADH2
Una vez completamente reducida, FNR transfiere los dos electrones a NADP+ .
En resumen, la cadena de transporte ETC en PSI sigue los siguientes pasos:
P700∗ → A → A0 → A1 → Fx → FA → FB → Fdx → FNR – NADPH
OXIGEN EVOLVING CENTER OEC
Con la síntesis de NADPH y la habilitación de síntesis de ATP mediante la generación de fuerza protomotríz PMF por el sistema parecería que el tema quedaría cubierto.
Sin embargo queda pendiente el tema de reposición de electrones en PSII para que la maquinaria fotosintética pueda operar ininterrumpídamente.
La oxidación de P680 inicializa el fljo ETC mediante la cesión electrónica, pero a su vez, gracias al alto poder oxidante adquirido, permite reincorporarlos desde la fuente primaria, H2O, mediante una innovacion evolutiva, El ciclo de Joliot-Kokmediado por Mn4CaO5 , ciclo que opera en un complejo proteínico denominado Oxigen Evolving Center, “OEC”.
Como core del complejo OEC y como centro oxidante se presenta una molécula de estructura cubana, ver Fig 13, y fórmula molecular Mn4CaO5, responsable final de la oxidación del agua.
Figura 13. Diagrama 3D de la molécula Mn4CaO5. Se incluyen en la molécula las cuatro moléculas coordinadas de agua
El tránsito de electrones desde MnCaO5 hacia el par de clorofilas es mediado por un residuo Tyr 161 (Yz), en la secuencia
H2O → Mn4CaO5 → Yz → P680*
Al ceder electrones, P680* adquiere un potencial oxidativo muy alto (~+1,25v) , lo que permite oxidar Tyr161 quien a su vez oxida MnCaO5 para que tras un ciclo repetido pueda oxidar el agua , ver Fig.14.
Figura 14. Ciclo de KOK. Las cuatro barras en cada estado representan los cuatro átomos de manganeso, barras azules indican átomos en estado de oxidación III, barras rojas estado IV.
Como etapa previa al ciclo de KOK, la energía de un fotón procedente del complejo antena promueve la liberación de un electrón en P680, lo que lo lleva a un estado P680* altamente oxidativo. Este potencial es transladado al centro OEC con el propósito final de oxidación del H2O.
El elemento responsable de los estados de potencial corresponde a los cuatro átomos de Mn, que pueden tener los siguientes estados de oxidación:
Las etapas del ciclo de KOK se pueden resumir así:
S0 → S1: Partiendo de un estado inicial en Mn4CaO5 con Mn1 – Mn3 en estado de oxidación III y Mn4 en estado de oxidación IV, P680* promueve la oxidación de Tyr161 y luego la oxidación de Mn3 en Mn4CaO5 (con la consecuente reposición electrónica en P680), lo que genera en el core de OEC un potencial de +0,8v.
S1 →S2: Segundo fotón incidente, segundo electrón liberado, se eleva el potencial oxidativo del core a de +0,8v a 0,9v , oxidación de Mn2 pasando del estado MnIII a MnIV, liberación de H+ al lumen thylakoide.
S2 →S3: Tercer fotón incidente, tercer electrón liberado, captura de una primera molécula de agua, liberación de H+ al lumen thylakoide, el core adquiere un potencial de ~+1,0 – +1,1, oxidación de Mn1 pasando del estado MnIII a MnIV.
S3 →S4 → S0: Cuarto fotón incidente y cuarto electrón liberado. Con todos los átomos de Mn en estado de oxidación +IV, el potencial de oxidación general es lo suficientememnte alto como para generar un enlace O-O a partir de H2O, de manera que sus electrones se puedan incorporan al sistema, retornando de paso los estados de oxidación de los átomos de Mn a sus condiciones iniciales para así poderse iniciar un nuevo ciclo.
S2 y S3 son estados metaestables, particularmente en ausencia o deficiencia de luz, pudiendo decaer el sistema a S0, lo que hace que el poder oxidante acumulado se pierda.
La secuencia presentada se basa en un modelo de oxidación de “valencia alta” (High valence), caracterizada por átomos de Mn en estados de oxidación III y IV.
Este modelo presupone en la etapa S4, previa la formación del enlace O-O, la oxidación de un átomo de Mn a un estado V, estado energéticamente extremo, difícil de explicar bajo el modelo de Lewis y en conflicto con algunos datos espectroscópicos experimentales.
Una segunda alternativa se basa en un modelo de bajo potencial (Low potential), en el que no es necesario recurrir a estados de oxidación extremos y donde la energía adicional es resuelta mediante Radicales Oxyl (O.), Puentes Oxo deprotonados y Oxidación centrada en ligandos, y no en los átomos de Mn.
Bajo este modelo, el manganeso Mn1 participa en S0 con un estado de oxidación II , y en general, a lo largo de todo el ciclo, los estados de oxidación del core son menores que los del modelo de potencial alto, ver Fig 15.
Este modelo explica de mejor manera el ciclo, no es necesario recurrir a estados energéticos extremos, pero por otro lado el hecho de manejar menores potenciales de oxidación abre interrogantes sobre la capacidad de oxidación del agua.
Para concluir, la sinergia bioquímica resultante de combinar los fotosistemas PSII y PSI en una única maquinaria fotosintética fuertemente oxidante y a la vez fuertemente reductora, sumado al desarrollo de un novedoso complejo bioquímico diseñado para extraer electrones del agua, permitió que toda una nueva propuesta bioquímica, la de las formas de vida aerobia, conquistara el planeta en una explosión evolutiva que aún hoy, después de 2,500 millones de años, nos acompaña.
Lidiar con el oxígeno, sin embargo, no ha sido tarea fácil para la vida, e incluso la maquinaria fotosintética que lo liberó por primera vez debe lidiar con él.
Los mecanismos de protección ROS, y en general las rutas de control diseñadas para proteger la maquinaria fotosintética, serán el tema de la próxima lectura.
Las bacterias verdes del azufre son un grupo bacteriano Gram (-) fotolitoautótrofo metabólicamente especialista, pertenenecen a la clase Chlorobia, Phyllum Bacteroidotas, caracterizadas por ser anaerobias estrictas .
Propias de ambientes anóxicos en fondos de lagos con alto contenido de azufre, utilizan H2S y en menor medida tiosulfatos y So elemental como donores de electrones, carecen del ciclo reductor de Calvin-Benson, en reemplazo fijan CO2 mediante el ciclo reverso del ácido tricarboxílico.
Su aparato fotosintético contiene complejos antena altamente eficientes denominados clorosomas, los cuales les permiten prosperar a bajísimas intensidades de luz, siendo de hecho el grupo fotosintetizador con menores requerimientos de energía lumínica reportado a la fecha.
Este grupo bacteriano utiliza el centro de reacción RC para producir reductantes fuertes, ATP y NADPH, mediante la oxidacion de los compuestos del azufre anteriormente mencionados.
Para activar la cadena de transporte de electrones, RC contiene como cofactor prostético un par de bacterioclorofilas BChla exitable a 840 nm, que les permite pasar de un estado GND un estado exitado P840*, ver Fig. 1.
Figura 1. Potenciales REDOX en la cadena ETC de las bacterias verdes del azufre.
P840 es indispensable para:
Recepción de energía lumínica proveniente de los complejos antena
Separación de cargas
Transferencia de electrones a clusters de proteinas-ferrodoxinas Fe–S, a niveles de energía mucho menores (mas negativos) que los requeridos por las quinonas de bacterias púrpura, lo que permite reducir directamente NAD+.
ETC transfiere la energía desde el par BChla exitado hacia FeSA/B, y finalmente a ferrodoxinas Fd citoplasmáticas altamente reductoras, (514-584 mV) , lo que proporciona potenciales suficientes para reducir NADP + vía ferrodoxina/NADP+ oxidoreductasa, lo que habilita las cadenas memtabólicas responsables de la fijación de carbono.
En cuanto a la síntesis de ATP, a la fecha no hay claridad sobre la ruta responsable de generación de la PMF requerida para la activación de ATP synthase.
En primer lugar, en la cadena de transporte de electrones no participan de manera directa quinonas, y solo menaquinona MK7 está presente en lo que prodría definirse como pool de quinonas.
Por otro lado, a pesar de que GSB contiene genes codificantes de Cyt b y Rieske Fe/S (PetB y PetC respectivamente), no ha sido descrito a la fecha genoma codificador de Cyt c1 y Cyt f , de manera que una ruta cíclica equivalente a la vía Cyt bc1 de bacterias púrpura no ha sido demostrada para GSB. El rol de Cyt b y Rieske Fe/S en el complejo es sujeto de investigación.
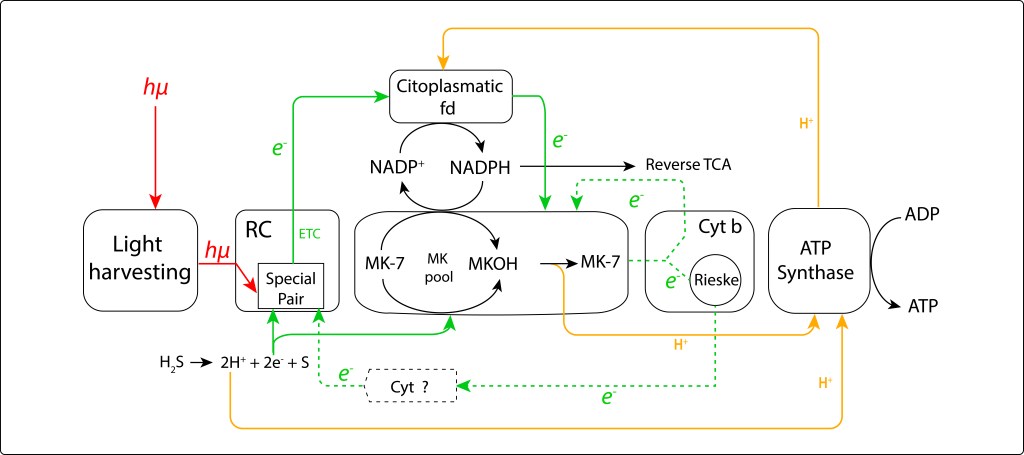
De manera alterna, es posible que la acción combinada de ferredoxina como agente reductor de MK7 y NADP deshidrogenasa como fuente de protones, ver Fig.2., permita generar MKOH, de modo que la translocación de protones en una etapa oxidativa subsiguiente de MKOH -> MK7 para síntesis de ATP pueda ocurrir . La reducción de MK7 puede tambien provenir de FeS o la fuente de electrones del sistema. Independiente del agente reductor, no ha sido posible caracterizar complejos oxidantes de MKOH que soporten la teoría, así que la ruta de generación de PMF y retorno de electrones al sistema en alguna vía alterna a Cytc1-Cyt C soluble también está por aclararse. En la Fig 2., las líneas punteadas representan rutas probables no demostradas.
Figura 2. Diagrama de flujo de las probables rutas fotosintéticas en GSB, incluyendo consumo de NADPH para síntesis de ATP. Líneas punteadas indican rutas no demostradas.
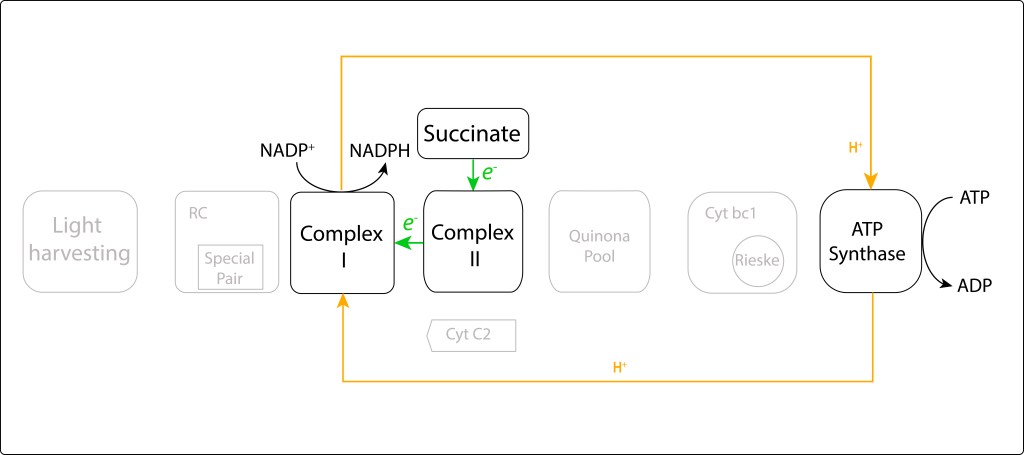
Para complementar el tema, la Fig 3 describe la ruta de síntesis de NADPH en bacterias púrpura mediante el consumo de ATP.
Figura 3. Diagrama de flujo de la síntesis de NADPH a partir de consumo de ATP en bacterias ´púrpura
En resumen, mientras que en bacterias púrpura, debido a su naturaleza débilmente reductora, se hace necesario “invertir” parte del ATP producido para sintetizar NADPH, en GSB, dada su naturaleza fuertemente reductora pero débilmente oxidante, una fracción de NADPH es la que se debe utilizar durante la síntesis de ATP.
Puesto que la incorporación de carbono a partir de CO2 depende de la disponibilidad tanto de NADPH como de ATP en las rutas reductoras (Ciclo de Calvin-Benson y TCA Reverso, entre otros) , y puesto que parte de estos agentes debe ser direccionado hacia la síntesis de los mismos, los aparatos fotosintéticos de Bacterias púrpura y GSB tienen en común una eficiencia limitada. La situación en bacterias púrpura y GSB recuerda la paradoja de la serpiente, quien para sobrevivir, requiere alimentarse de sí misma.
Figura 4. Paradoja de la serpiente
Hace unos 2,000 millones de años, en un proceso de endosimbiosis bioquímica, dos grupos bacterianos, con rutas bioquímicas similares a las mencionadas, fusionaron de alguna manera sus maquinarias fotosintéticas dando origen a un único complejo fuertemente oxidante, fuertemente reductor, lo que por un lado eliminó la necesidad de consumo de productos reductores para síntesis de sí mismos, y por otro lado habilitó la utilización de H2O como una nueva e ilimitada fuente de electrones.
Las consecuencias de dicha convergencia evolutiva marcaron un punto de inflexión en la vida en el planeta, pero esto será tema para las próximas lecturas.
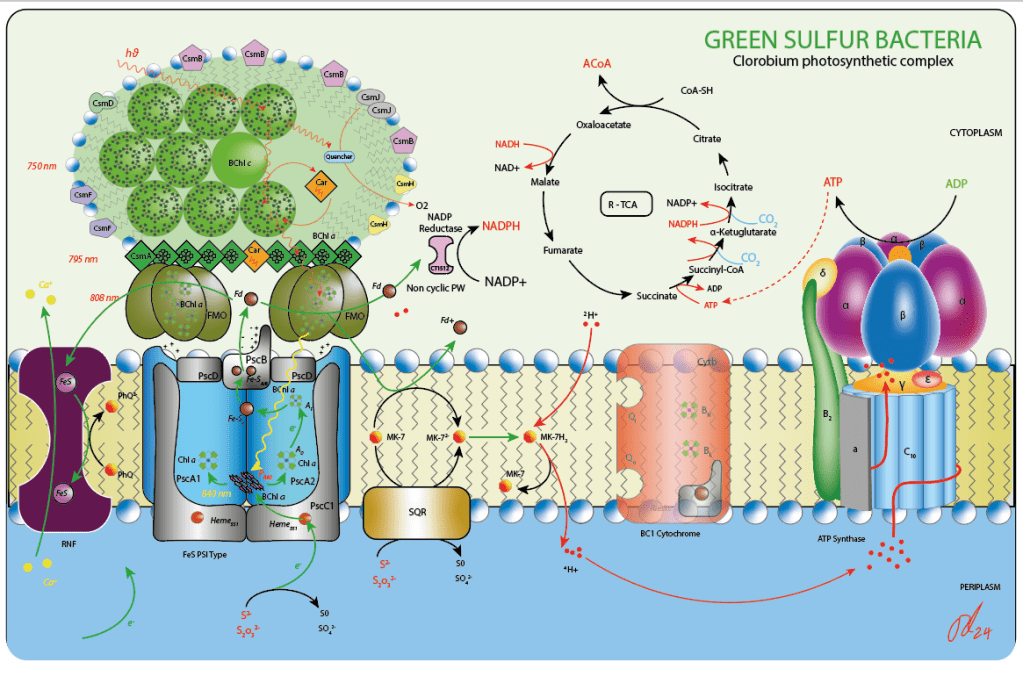
Finalmente, y para cerrar la lectura, la figura 5 desribe de manera resumida el aparato fotosintético en GSB.
Figura 5. Aparato fotosintético en bacterias verdes del azufre