La “Fosforilación oxidativa” corresponde al proceso de captura de energía por parte de los organismos con respiración celular aerobia, incluyendo eucariotas (plantas, animales, hongos y protistas) y procariotas (bacterias y arqueas aerobias).
El término “Fosforilación oxidativa” resume de la mejor manera su función: “Fosforilación”, como objetivo, pues se trata de una maquinaria orientada a ACUMULAR ENERGÍA representada por radicales en ATP, y por otro lado “Oxidativa”, como requisito, pues la maquinaria opera mediante la oxidación (o extración de energía) de las coenzimas NADH y FDH2 procendentes del ciclo del Ácido Tricarboxílico (TCA) .
TCA a su vez opera como un intermediario en el tránsito de energía entre moléculas ricas en energía (carbohidratos y ácidos grasos) y la maquinaria fosforilativa.
PROCESO
La glucosa, donador principal de energía a la maquinaria fosforilativa, ingresa a la célula por dos vías:
1. A favor de gradiente (Difusión Facilitada) , sin requerirse ATP en el proceso, mediante transportadores de glucosa (GLUT).
2. En contra de gradiente (Trasporte Activo Secundario) mediante transportadores SGLT (Sodium-Glucose Linked Transporter), aprovechando las bombas Na⁺/K⁺ .
La familia de transportadores GLUT comprende 14 proteinas 12-transmembrana, GLUT1 a GLUT14, agrupadas en tres clases, todas con las terminales N y C expuestas al citoplasma.
El transportador GLUT4, en particular, es regulado por la insulina, cuya presencia en el torrente sanguineo inicia un proceso de transducción de señal que al completarse permite que GLUT-4 (almacenado en vesículas libres) se incorpore a la membrana celular para cumplir su función de transporte de glucosa hacia el citosol.
La regulación de glucosa por la insulina se sale de los objetivos de la presente lectura, pero definitivamente justifica un lectura aparte.
En el citosol, por la ruta de la glicólisis, cada molécula de glucosa es convertida en dos moléculas de Piruvato, las cuales ingresan a la mitocondria, también mediante difusión facilitada, con la participación de una proteína especializada presente en la membrana interna mitocondrial denominada MPC (Mitochondrial Pyruvate Carrier).
Finalmente, al interior de la mitocondria, el Piruvato cede su radical Acetil a la Coenzima A (CoA) mediante la enzima Piruvato-deshidrogenasa, lo que permite generar Acetil-Coenzima A (ACoA), molécula que activa el ciclo del ácido tricarboxílico o ciclo de Krebs. ACoA también es generado por radicales acil provenientes de la Beta-Oxidación de ácidos grasos, los cuales ingresan a la mitocondria en forma de Acil-Carnitina.
ACoA incorpora los dos carbonos del radical acil al oxaloacetato para regenerar citrato, lo que de paso define el nombre alterno del TCA (Ciclo del ácido cítrico).
TCA existe con el propósito fundamental de abastecer de combustible a la cadena fosforilativa en forma de FADH2 y NADH. Por cada molécula de glucosa se producen seis moléculas de NADH, dos de FADH2 y dos moléculas de GTP.
La maquinaria responsable de la fosforilación oxidativa (activada por NADH y FADH2) comprende cuatro complejos bioquímicos, numerados I a IV, los cuales tienen como función en conjunto generar un gradiente protónico entre la matriz y el espacio intermembrana de la mitocondria. Este gradiente a su vez alimenta la ATP Synthasa, lo que permite acumular energía en forma de ATP, de manera similar a como lo hacen los complejos fotofosforilativos en los organismos fotosintetizadores y a la fosforilación quimiosmótica propia de algunas bacterias y arqueas anaerobias (E. coli, desulfovibrio y arqueas metanógenas).
COMPELEJO I: NADH-UBIQUINONA OXIDOREDUCTASA
Encargado de la captura de energía almacenada en NADH, bombea cuatro iones H+ por cada molécula de NADH que ingresa al complejo. En el bombeo iónico participan numerosas moléculas de agua precisamente dispuestas al interior de las subunidades proteicas transmembrana PD y PP. (subunidades Distal y proximal transmembrana respectivamente), si bién su participación y manera de acción no está bién entendida.
El bombeo de protones contra gradiente es habilitado mediante una cadena de transporte de electrones (ETC) en el sentido NADH -> Ferredoxinas -> Ubiquinona , culminando con la reducción de la Ubiquinona y exportación de la misma en forma de Ubiquinol al pool de quinonas.
COMPLEJO II: SUCCINATO-UBIQUINONA OXIDOREDUCTASA
Es el único de los cuatro complejos que no realiza transporte de protones desde la matriz hacia el espacio intermembrana. De igual manera, único complejo intimamente Ligado al TCA, concretamente en la etapa de oxidación de Succinato a Fumarato, reduciendo FAD a FADH2, lo que activa una cadena de transporte de electrones en el sentido FADH2 -> Ferrredoxinas -> Heme -> Ubiquinona, las cuales finalmente son exportadas al pool de quinonas en su forma reducida.
COMPLEJO III: CITOCROMO bc1
Aceptor de las quinonas reducidas exportadas por los complejos I y II, captura los electrones del ubiquinol liberando 2 H+ por molécula los cuales se exportan al espacio intermembrana contribuyendo al gradente protónico (PMF).
Citocromo bc1 , al igual que b6f en los complejos fotosintéticos, enruta el primer electrón producto de la oxidación de la molécula de ubiquinol hacia una cadena de transporte de electrones compuesta por dos hemes BL -> BH para en el sitio Qi reducir parcialmente una molécula oxidada UQ2+ -> UQ+ . El segundo electrón es enrutado hacia el complejo Rieske proximal al espacio intermembrana, de allí a Cyt c1 y finalmente al cyt c soluble que se mueve hacia el complejo IV. El proceso reductor se repite para reducir completamente la ubiquinona parcialmente reducida UQ+ -> UQ2+ permitiendo regenerar en el pool de quinonas el primer ubiquinol extraído.
COMPLEJO IV: CITOCROMO C OXIDASA
Responsable del destino final de los electrones producto de las cadenas ETC de la maquinaria fosforilativa, produce agua a partir de O2 y H+ presentes en la matriz mitocondrial.
El complejo IV contribuye al PMF por dos vías: Por un lado consumiendo H+ en la matriz mitocondrial, y por otro lado transportando activamente H+ de la matriz hacia el espacio intermembrana, proceso mediado por su propia cadena ETC .
El complejo IV contiene dos centros de cobre:
- Centro CuA: Contiene dos iones de cobre, siendo responsable de recibir los electrones provenientes de CytC, para luego transferirlos al centro catalítico CuB del complejo.
- Centro CuB: Contiene un ión de cobre, que junto con un Heme a3 recibe los electrones de CuA para reducir completamente O2 a H2O evitando de paso que los electrones libres formen especies reactivas de oxígeno.
ATP SYNTHASE
Aunque técnicamente no forma parte del aparato fosforilativo, este complejo es el encargado de aprovechar el gradiente protónico para sintetizar ATP a partir de ADP, propósito único de la fosforilación oxidativa.
ATP Sintasa es una verdadera máquina ensambladora rotativa de tres tiempos: Admisión -> Compresión -> Expulsión, con sus centros activos separados 120° entre sí, utiliza para la rotación el gradiente protónico H+ generado por el aparato fosforilativo.
En algunas bacterias marinas anaerobias halófilas, propias de ambientes muy alcalinos, donde H+ no puede operar, ATP Sintasa utiliza de manera alternativa Na+ para generar la rotación requerida para la síntesis de ATP.


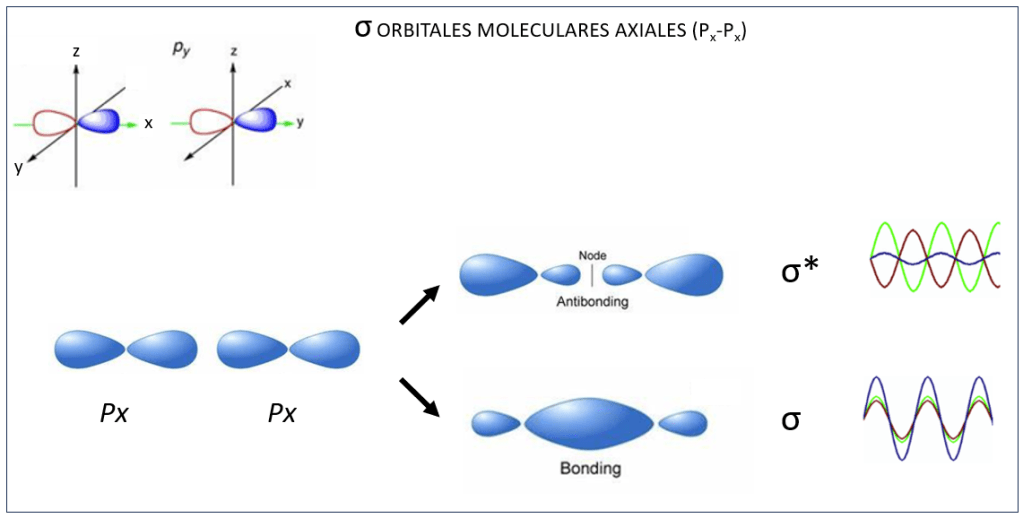
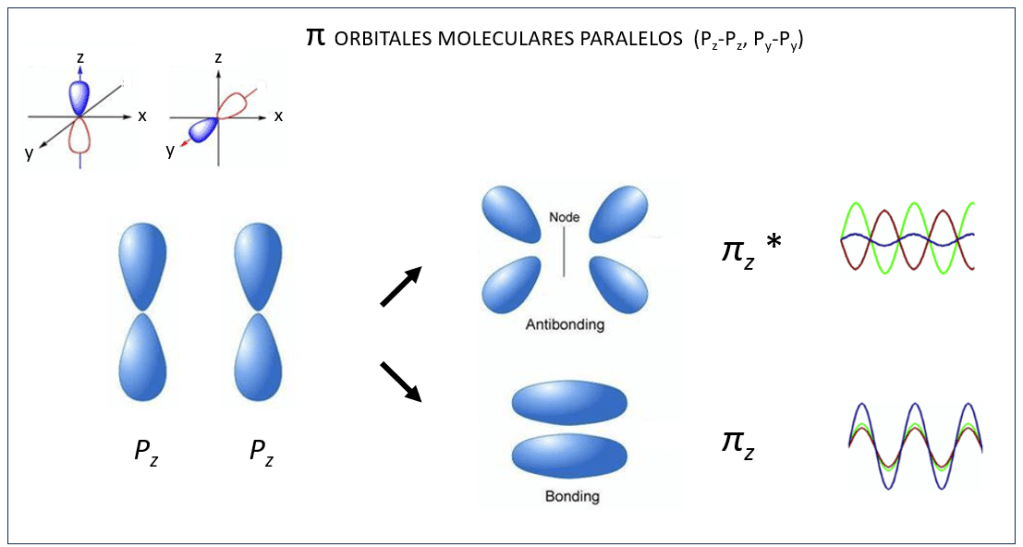

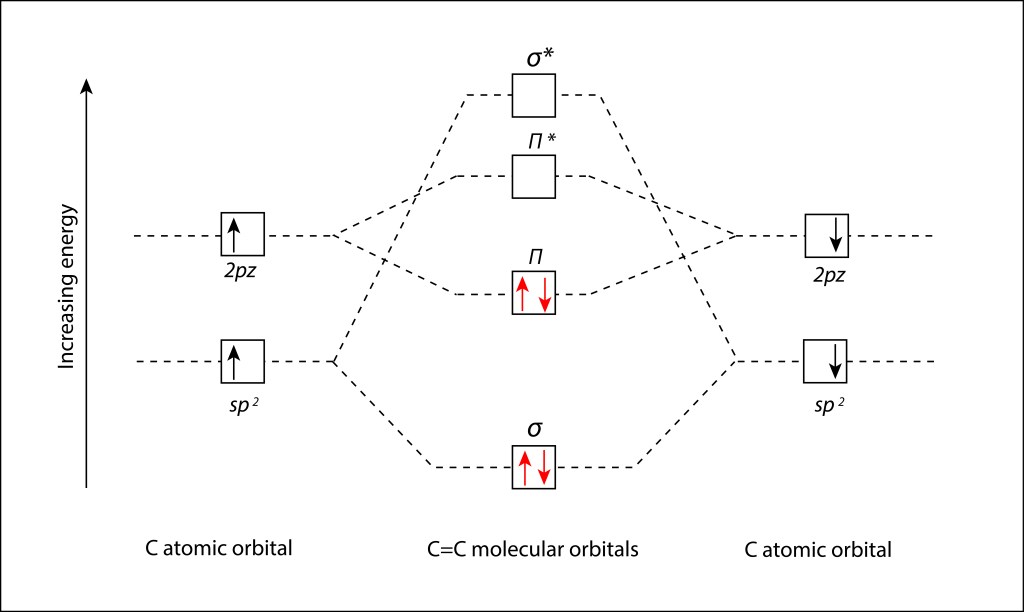



 , corresponden a los siguientes eigenspinors:
, corresponden a los siguientes eigenspinors: